

Demos
Multitrack Single Microphone Switcher
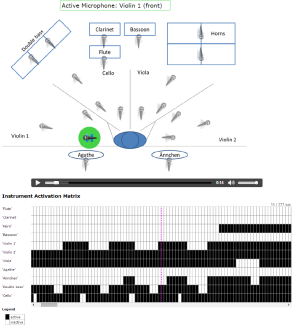
The Single Microphone Switcher is a demo for exploring the recordings of the individual microphones used in the Freischütz Multitrack Dataset recordings. It sketches how the microphones were positioned in the room. The interface provides the possibility to listen to the individual microphone recordings. Furthermore, the instrument activation matrix, provides a visualization that shows which instruments are currently active (black) or inactive (white) at the current playback position.
Instrument Equalizer

An instrument equalizer provides the possibility to adjust the volume of an individual instrument in a recording without affecting the volume of the other instruments. This demo provides a multitrack audio player with an individual track for each voice/instrument of No. 6 from "Der Freischütz". When studying a specific melody line of the violins and the flutes, for example, the instrument equalizer enables a user to raise the volume for these two voices and to lower it for the others. Note that, when recording orchestra music, the microphones for capturing the different voices are usually not shielded from each other. In practice, each microphone not only records sound from its dedicated voice or instrument, but also from all others in the room. This results in recordings that do not feature isolated signals, but rather mixtures of a predominant voice with all others being audible through what is referred to as interference. We developed a method for reducing interferences in multitrack recordings. A way to use multitrack recordings suffering from interference in an instrument equalizer is to apply an interference reduction first.
Score Follower & Interpretation Switcher

The goal in score following is to retrieve the current score position in a sheet music representation while playing back a corresponding music recording. Similarly, the goal in interpretation switching is to to retrieve the time positions in different recordings that correspond to the current playback position of a given music recording. In this demo, we show a web-based audio player providing score following and interpretation switching functionalities. During the playback of a recording, the corresponding position in the musical score is highlighted. The user can choose between scans of historical scores (facsimiles) or a rendering of a digitally encoded score in MEI. To display the MEI score, we use the library Verovio. Furthermore, a list of available audio versions is shown. Simultaneously to the playback of the active audio version (marked in blue on the left side), the corresponding time positions in all available audio versions is displayed. When selecting another audio version, the player switches seamlessly to the chosen version and starts the playback at the position that corresponds to the time position of the previously active audio version. The score following and interpretation switching is realized by providing offline alignments between the different audio versions and the musical score.
Kernel Additive Modeling for Interference Reduction in Multi-Channel Music Recordings
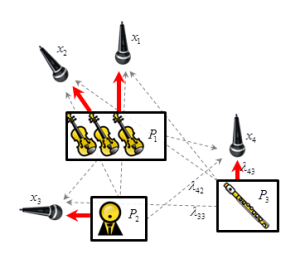
When recording a live musical performance, the different voices, such as the instrument groups or soloists of an orchestra, are typically recorded in the same room simultaneously, with at least one microphone assigned to each voice. However, it is difficult to acoustically shield the microphones. In practice, each one contains interference from every other voice. In this paper, we aim to reduce these interferences in multi-channel recordings to recover only the isolated voices. Following the recently proposed Kernel Additive Modeling framework, we present a method that iteratively estimates both the power spectral density of each voice and the corresponding strength in each microphone signal. With this information, we build an optimal Wiener filter, strongly reducing interferences. The trade-off between distortion and separation can be controlled by the user through the number of iterations of the algorithm. Furthermore, we present a computationally efficient approximation of the iterative procedure. Listening tests demonstrate the effectiveness of the method.
Let it Bee - Towards NMF-inspired Audio Mosaicing
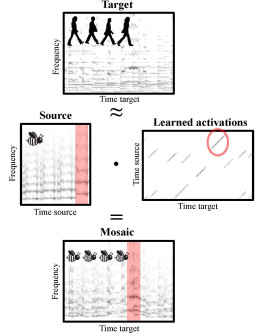
A swarm of bees buzzing “Let it be” by the Beatles or the wind gently howling the romantic “Gute Nacht” by Schubert – these are examples of audio mosaics as we want to create them. Given a target and a source recording, the goal of audio mosaicing is to generate a mosaic recording that conveys musical aspects (like melody and rhythm) of the target, using sound components taken from the source. In this work, we propose a novel approach for automatically generating audio mosaics with the objective to preserve the source’s timbre in the mosaic. Inspired by algorithms for non-negative matrix factorization (NMF), our idea is to use update rules to learn an activation matrix that, when multiplied with the spectrogram of the source recording, resembles the spectrogram of the target recording. However, when applying the original NMF procedure, the resulting mosaic does not adequately reflect the source’s timbre. As our main technical contribution, we propose an extended set of update rules for the iterative learning procedure that supports the development of sparse diagonal structures in the activation matrix. We show how these structures better retain the source’s timbral characteristics in the resulting mosaic.
Score-Informed Audio Decomposition and Applications
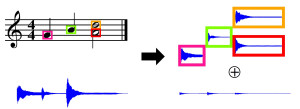
The separation of different sound sources from polyphonic music recordings constitutes a complex task since one has to account for different musical and acoustical aspects. In the last years, various score-informed procedures have been suggested where musical cues such as pitch, timing, and track information are used to support the source separation process. In this paper, we discuss a framework for decomposing a given music recording into notewise audio events which serve as elementary building blocks. In particular, we introduce an interface that employs the additional score information to provide a natural way for a user to interact with these audio events. By simply selecting arbitrary note groups within the score a user can access, modify, or analyze corresponding events in a given audio recording. In this way, our framework not only opens up new ways for audio editing applications, but also serves as a valuable tool for evaluating and better understanding the results of source separation algorithms.