Abstract
When recording a live musical performance, the different voices, such as the instrument groups or soloists of an orchestra, are typically recorded in the same room simultaneously, with at least one microphone assigned to each voice. However, it is difficult to acoustically shield the microphones. In practice, each one contains interference from every other voice. In this paper, we aim to reduce these interferences in multi-channel recordings to recover only the isolated voices. Following the recently proposed Kernel Additive Modeling framework, we present a method that iteratively estimates both the power spectral density of each voice and the corresponding strength in each microphone signal. With this information, we build an optimal Wiener filter, strongly reducing interferences. The trade-off between distortion and separation can be controlled by the user through the number of iterations of the algorithm. Furthermore, we present a computationally efficient approximation of the iterative procedure. Listening tests demonstrate the effectiveness of the method.
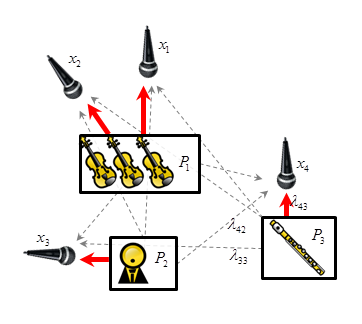
Audio Examples
In the following we present audio examples that are excerpts of a multi-channel recording of the opera
“Der Freischütz”. On each of the excerpts, the KAMIR (Kernel Additive Modeling for Interference Reduction) algorithm has been applied in different parameter settings.
Additionally, the algorithm presented in Kokkinis 2012 [1] has been applied to the excerpts.
You can click on the microphone symbols to start the playback of an individual microphone channel.
Furthermore, you can select different excerpts and switch between the original signal, the processings of KAMIR (K1, K2, K3, K4, K5) and the processing of the algorithm from Kokkinis 2012 [1].
Select algorithm
Audio Files from the Subjective Evaluation
The following table lists the items that were used in the conducted listening test. The original (unprocessed) version of a microphone channel was presented together with 5 processings of KAMIR (K1, K2, K3, K4, K5) and a processing of the algorithm from Kokkinis 2012[1].| Item | Original | Kokkinis2012 | K1 | K2 | K3 | K4 | K5 |
|---|---|---|---|---|---|---|---|
| singer | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] |
| violine | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] |
| horns | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] |
| clarinet | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] |
| cello | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] | [wav] |
References
- [1]
-
E. Kokkinis, J. Reiss, and J. Mourjopoulos,
A Wiener filter approach to microphone leakage reduction in closemicrophone applications,
In IEEE Transactions on Audio, Speech & Language Processing, vol. 20, no. 3, pp. 767–779, 2012.