

Demos
Template-Based Vibrato Analysis of Music Signals
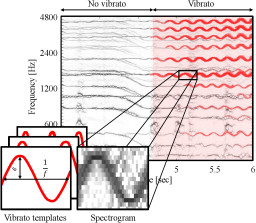
The automated analysis of vibrato in complex music signals is a highly challenging task. A common strategy is to proceed in a two-step fashion. First, a fundamental frequency (F0) trajectory for the musical voice that is likely to exhibit vibrato is estimated. In a second step, the trajectory is then analyzed with respect to periodic frequency modulations. As a major drawback, however, such a method cannot recover from errors made in the inherently difficult first step, which severely limits the performance during the second step. In this work, we present a novel vibrato analysis approach that avoids the first error-prone F0-estimation step. Our core idea is to perform the analysis directly on a signal's spectrogram representation where vibrato is evident in the form of characteristic spectro-temporal patterns. We detect and parameterize these patterns by locally comparing the spectrogram with a predefined set of vibrato templates. Our systematic experiments indicate that this approach is more robust than F0-based strategies.
Let it Bee - Towards NMF-inspired Audio Mosaicing
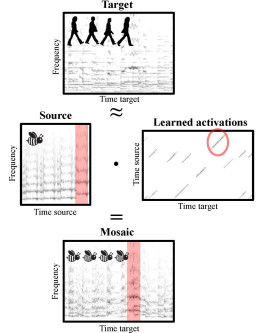
A swarm of bees buzzing “Let it be” by the Beatles or the wind gently howling the romantic “Gute Nacht” by Schubert – these are examples of audio mosaics as we want to create them. Given a target and a source recording, the goal of audio mosaicing is to generate a mosaic recording that conveys musical aspects (like melody and rhythm) of the target, using sound components taken from the source. In this work, we propose a novel approach for automatically generating audio mosaics with the objective to preserve the source’s timbre in the mosaic. Inspired by algorithms for non-negative matrix factorization (NMF), our idea is to use update rules to learn an activation matrix that, when multiplied with the spectrogram of the source recording, resembles the spectrogram of the target recording. However, when applying the original NMF procedure, the resulting mosaic does not adequately reflect the source’s timbre. As our main technical contribution, we propose an extended set of update rules for the iterative learning procedure that supports the development of sparse diagonal structures in the activation matrix. We show how these structures better retain the source’s timbral characteristics in the resulting mosaic.
Extracting Singing Voice from Music Recordings by Cascading Audio Decomposition Techniques
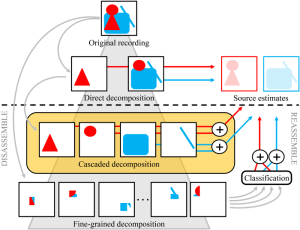
The problem of extracting singing voice from music recordings has received increasing research interest in recent years. Many proposed decomposition techniques are based on one of the following two strategies. The first approach is to directly decompose a given music recording into one component for the singing voice and one for the accompaniment by exploiting knowledge about specific characteristics of singing voice. Procedures following the second approach disassemble the recording into a large set of fine-grained components, which are classified and reassembled afterwards to yield the desired source estimates. In this paper, we propose a novel approach that combines the strengths of both strategies. We first apply different audio decomposition techniques in a cascaded fashion to disassemble the music recording into a set of mid-level components. This decomposition is fine enough to model various characteristics of singing voice, but coarse enough to keep an explicit semantic meaning of the components. These properties allow us to directly reassemble the singing voice and the accompaniment from the components. Our objective and subjective evaluations show that this strategy can compete with state-of-the-art singing voice separation algorithms and yields perceptually appealing results.
Extending Harmonic-Percussive Separation of Audio Signals
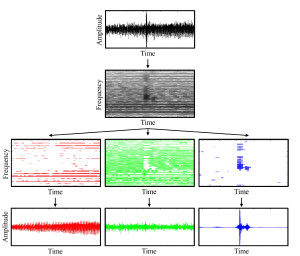
In recent years, methods to decompose an audio signal into a harmonic and a percussive component have received a lot of interest and are frequently applied as a processing step in a variety of scenarios. One problem is that the computed components are often not of purely harmonic or percussive nature but also contain noise-like sounds that are neither clearly harmonic nor percussive. Furthermore, depending on the parameter settings, one often can observe a leakage of harmonic sounds into the percussive component and vice versa. In this paper we present two extensions to a state-of-the-art harmonic-percussive separation procedure to target these problems. First, we introduce a separation factor parameter into the decomposition process that allows for tightening separation results and for enforcing the components to be clearly harmonic or percussive. As second contribution, inspired by the classical sines+transients+noise (STN) audio model, this novel concept is exploited to add a third residual component to the decomposition which captures the sounds that lie in between the clearly harmonic and percussive sounds of the audio signal.
Improving Time-Scale Modification of Music Signals using Harmonic-Percussive Separation
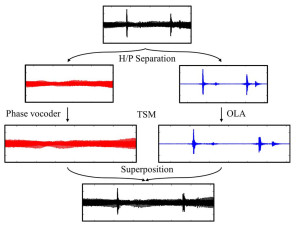
A major problem in time-scale modification (TSM) of music signals is that percussive transients are often perceptually degraded. To prevent this degradation, some TSM approaches try to explicitly identify transients in the input signal and to handle them in a special way. However, such approaches are problematic for two reasons. First, errors in the transient detection have an immediate influence on the final TSM result and, second, a perceptual transparent preservation of transients is by far not a trivial task. In this paper we present a TSM approach that handles transients implicitly by first separating the signal into a harmonic component as well as a percussive component which typically contains the transients. While the harmonic component is modified with a phase vocoder approach using a large frame size, the noise-like percussive component ismodified with a simple time-domain overlap-add technique using a short frame size, which preserves the transients to a high degree without any explicit transient detection.
Score-Informed Audio Decomposition and Applications
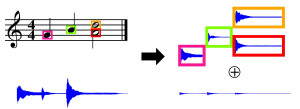
The separation of different sound sources from polyphonic music recordings constitutes a complex task since one has to account for different musical and acoustical aspects. In the last years, various score-informed procedures have been suggested where musical cues such as pitch, timing, and track information are used to support the source separation process. In this paper, we discuss a framework for decomposing a given music recording into notewise audio events which serve as elementary building blocks. In particular, we introduce an interface that employs the additional score information to provide a natural way for a user to interact with these audio events. By simply selecting arbitrary note groups within the score a user can access, modify, or analyze corresponding events in a given audio recording. In this way, our framework not only opens up new ways for audio editing applications, but also serves as a valuable tool for evaluating and better understanding the results of source separation algorithms.