

AmbiSep: Joint Ambisonic-to-Ambisonic Speech Separation and Noise Reduction
Adrian Herzog, Srikanth Raj Chetupalli and Emanuël A. P. Habets
Submitted to IEEE/ACM Transactions on Audio, Speech and Language Processing, December 2022.
Abstract
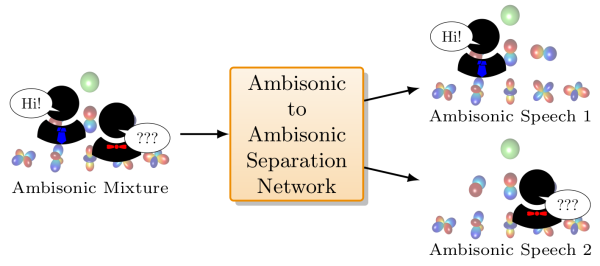
Blind separation of the sounds in an Ambisonic sound scene is a challenging problem, especially when the spatial impression of these sounds needs to be preserved. In this work, we consider Ambisonic-to-Ambisonic separation of reverberant speech mixtures, optionally containing noise. A supervised learning approach is adopted utilizing a transformer-based deep neural network, denoted by AmbiSep. AmbiSep takes mutichannel Ambisonic signals as input and estimates separate multichannel Ambisonic signals for each speaker while preserving their spatial images including reverberation. The GPU memory requirement of AmbiSep during training increases with the number of Ambisonic channels. To overcome this issue, we propose different aggregation methods. The model is trained and evaluated for first-order and second-order Ambisonics using simulated speech mixtures. Experimental results show that the model performs well on clean and noisy reverberant speech mixtures, and also generalizes to mixtures generated with measured Ambisonic impulse responses.
Notes
- All Ambisonic audio files were binauralized using the SPARTA AmbiBIN VST plugin [1]. Playback via headphones is recommended.
- Different source directions were used during training, validation and testing such that the models can generalize to arbitrary spatial arrangements of the sources.
- Some speech utterances of the WSJ-2mix dataset contain noise. This is different from the noise in Ex. 3 which was added in the Ambisonic domain.
- A comparison to baseline methods can be found here
Separation Methods
- AmbiSep: AmbiSep model with $N_L=1$ and $R=8$.
- AmbiSep-N: AmbiSep trained with white Gaussian noise, filtered by 50%.
- AmbiSep-NACE: AmbiSep trained with Ambisonic noise from ACE corpus~[2].
- AmbiSep-Ag1: AmbiSep with aggregation over chunks in interchunk transformers.
- AmbiSep-Ag2: AmbiSep with aggregation over chunks in interchannel and interchunk transformers.
- AmbiSep-Ag3: AmbiSep with aggregation over channels in intrachunk transformers and over channels+chunks in interchunk transformers.
- AmbiSep-Ag4: AmbiSep with aggregation over chunks in interchannel transformers, channels in intrachunk transformers and channels+chunks in interchunk transformers.
First-order Ambisonics
Example 1: Mixture with simulated impulse responses
Example 2: Mixture with recorded impulse resonses
Example 3: Mixture with simulated impulse responses and noise
Example 4: Recorded speech (with Eigenmike EM32 in Mozart)
Comparison of aggregation methods: Mixture with simulated impulse responses
Second-order Ambisonics
Example 1: Mixture with simulated impulse responses
Example 2: Mixture with recorded impulse resonses
Example 3: Mixture with simulated impulse responses and noise
Note: the AmbiSep was trained without noise. Therefore, there is some distorted noise in the separated speech signals.
References
[1] L. McCormack and A. Politis - SPARTA and COMPASS: Real-time implementations of linear and parametric spatial audio reproduction and processing methods, AES Conf. Immersive and Interactive Audio, York, UK, March 2019.
[2] J. Eaton, N. D. Gaubich, A. H. Moore and P. Naylor - The ACE challenge - corpus description and performance evaluation, in Proc. WASPAA, New Paltz, NY, USA, Oct. 2015.