

AmbiSep: Ambisonic-to-Ambisonic Reverberant Speech Separation Using Transformer Networks
Adrian Herzog, Srikanth Raj Chetupalli and Emanuël A. P. Habets
International Workshop on Acoustic Signal Enhancement (IWAENC), Bamberg, Germany, 2022.
Abstract
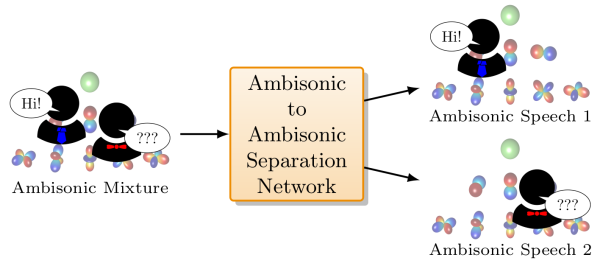
Consider a multichannel Ambisonic recording containing a mixture of several reverberant speech signals. Retreiving the reverberant Ambisonic signals corresponding to the individual speech sources blindly from the mixture is a challenging task as it requires to estimate multiple signal channels for each source. In this work, we propose AmbiSep, a deep neural network-based plane-wave domain masking approach to solve this task. The masking network uses learned feature representations and transformers in a triple-path processing configuration. We train and evaluate the proposed network architecture on a spatialized WSJ0-2mix dataset, and show that the method achieves a multichannel scale-invariant signal-to-distortion ratio improvement of 17.7 dB on the blind test set, while preserving the spatial characteristics of the separated sounds.
Notes
All Ambisonic audio files were binauralized using the SPARTA AmbiBIN VST plugin [1]. Playback via headphones is recommended. Note that the Ambisonic signals were rotated such that speaker 1 is always left and speaker 2 is always right before the binauralization for demonstration purposes. Different source directions were used during training, validation and testing such that the models can generalize to arbitrary spatial arrangements of the sources.
Separation Methods
- AmbiSep: Proposed triple-path transformer network-based architecture with $N_L=1$ and $R=8$.
- PWD-SF: SepFormer [2] with $N_L=1$ and $R=8$ per plane-wave domain channel and post transformer layer.
- Omni-SF: SepFormer [2] masknet with $N_L=8$ and $R=2$ on omnidirectional channel. The same masks are applied to all Ambisonic channels.
- Oracle Mask: Oracle Wiener masks are computed and applied in the learned time-feature domain.
Example 1 (female-male, angular separation 77°)
Example 2 (male-female, angular separation 142°)
Example 3 (female-female, angular separation 141°)
References
[1] L. McCormack and A. Politis - SPARTA and COMPASS: Real-time implementations of linear and parametric spatial audio reproduction and processing methods, AES Conf. Immersive and Interactive Audio, York, UK, March 2019.
[2] C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi and J. Zhong - Attention Is All You Need In Speech Separation, IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, June 2021.