Matching Reverberant Speech Through Learned Acoustic Embeddings and Feedback Delay Networks
Philipp Götz, Gloria Dal Santo, Sebastian J. Schlecht, Vesa Välimäki, and Emanuël A. P. Habets
Published in the Proc. of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026.
Abstract
Reverberation conveys critical acoustic cues about the environment, supporting spatial awareness and immersion. For auditory augmented reality (AAR) systems, generating perceptually plausible reverberation in real time remains a key challenge, especially when explicit acoustic measurements are unavailable. We address this by formulating blind estimation of artificial reverberation parameters as a reverberant signal matching task, leveraging a learned room-acoustic prior. Furthermore, we propose a feedback delay network (FDN) structure that reproduces both frequency-dependent decay times and the direct-to-reverberation ratio of a target space. Experimental evaluation against a leading automatic FDN tuning method demonstrates improvements in estimated room-acoustic parameters and perceptual plausibility of artificial reverberant speech. These results highlight the potential of our approach for efficient, perceptually consistent reverberation rendering in AAR applications.
Sound Examples
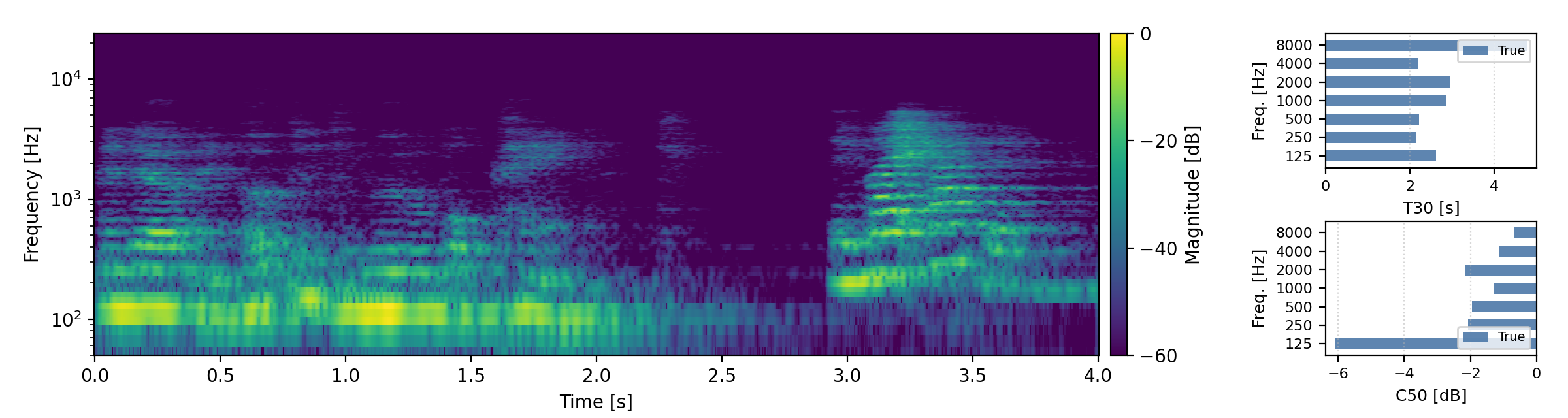
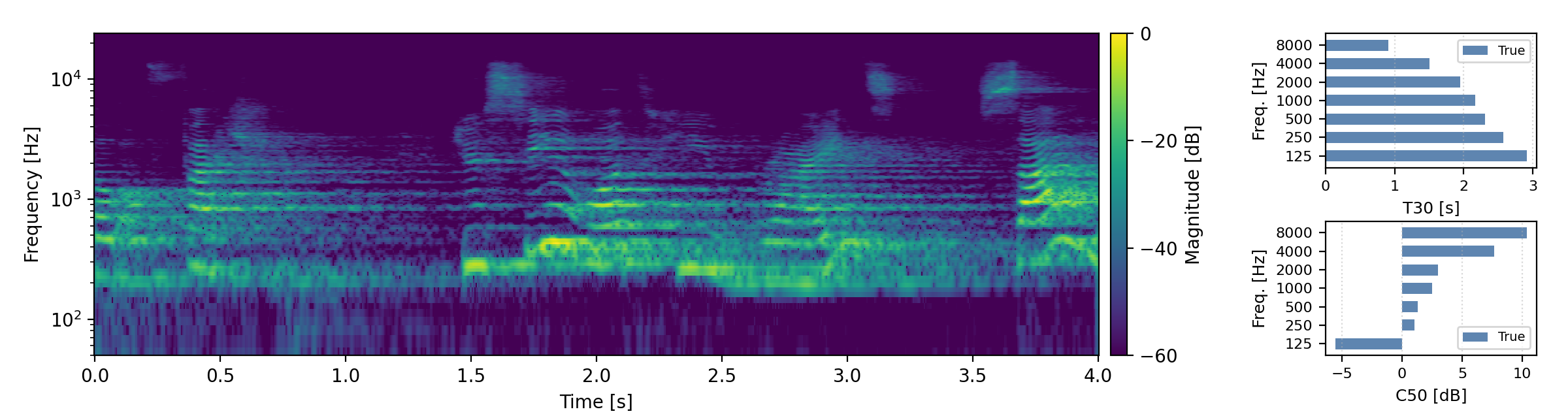
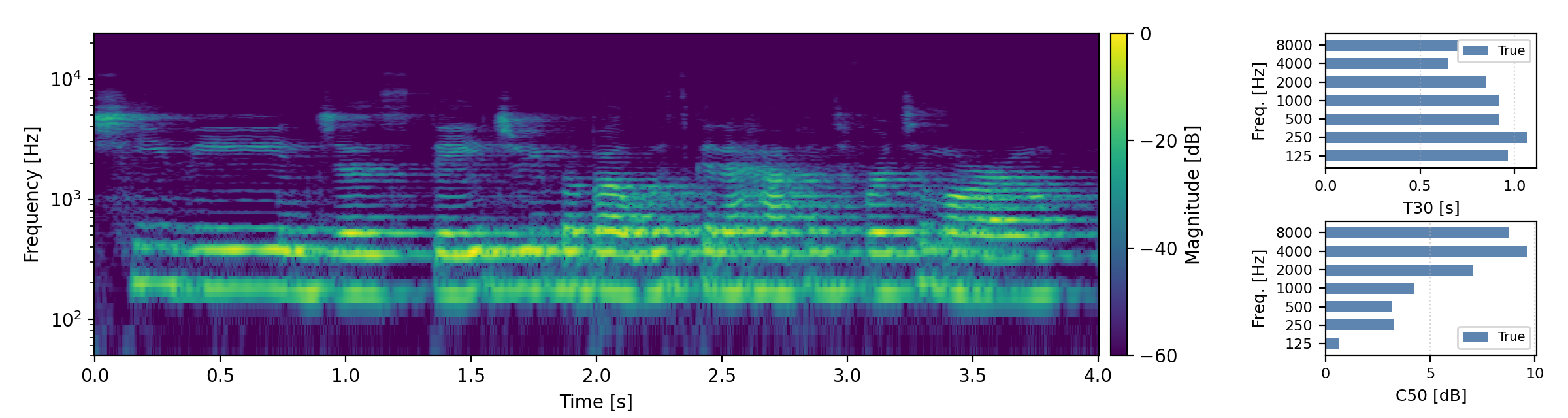
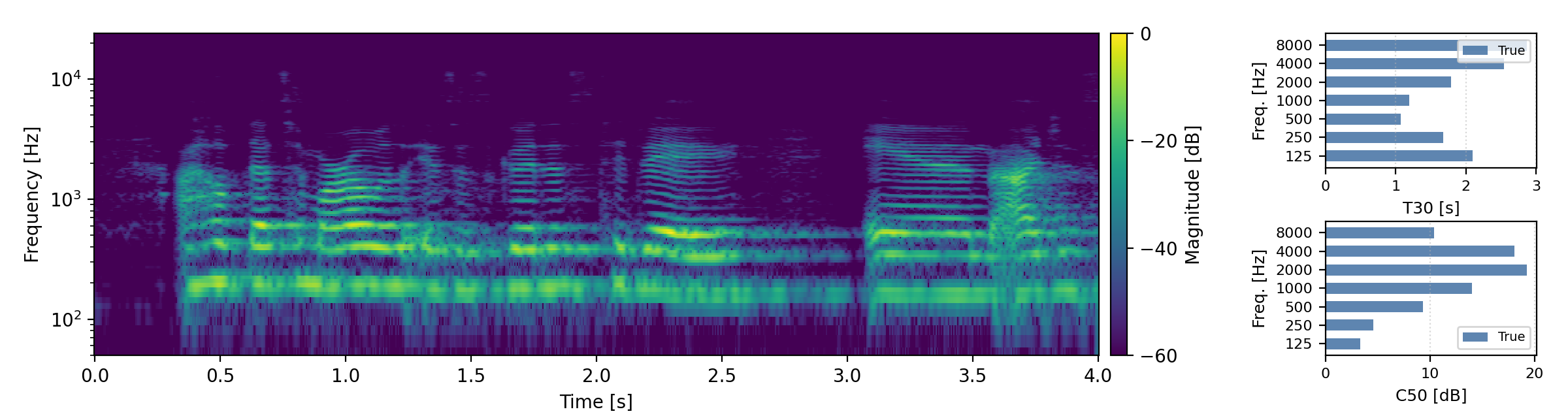
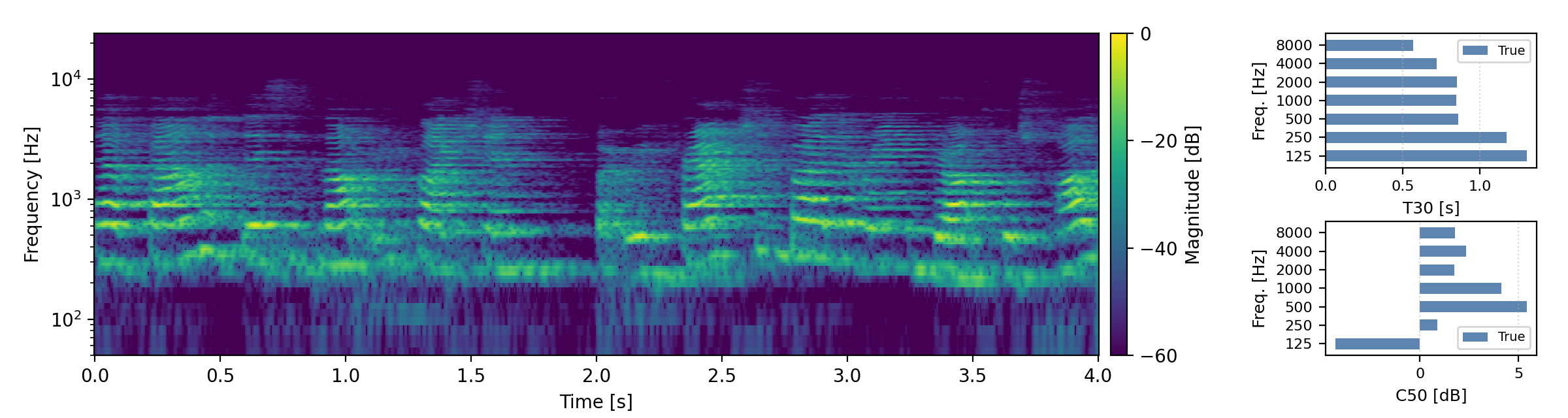
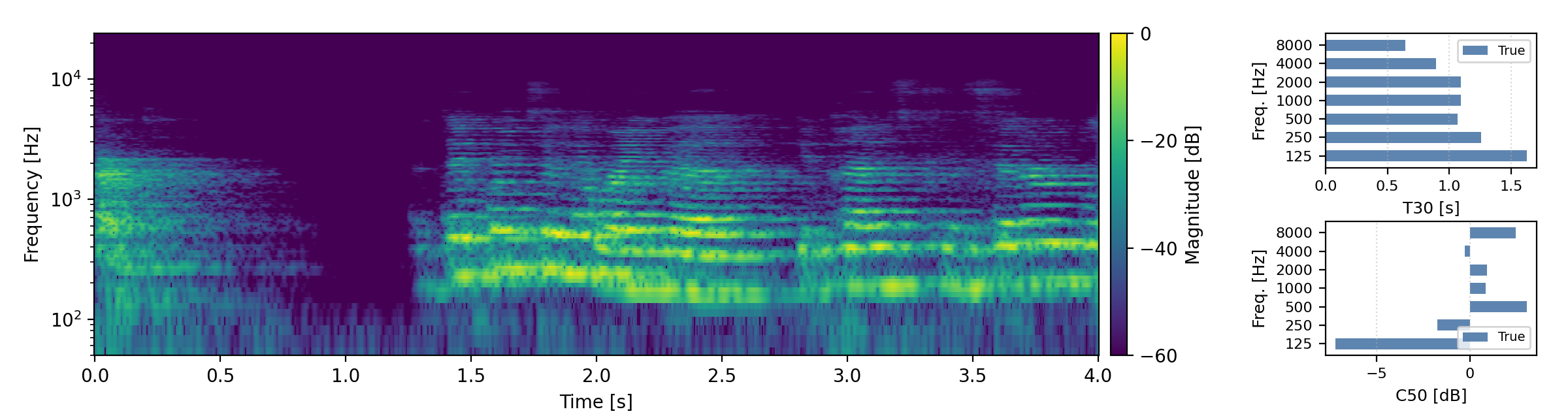
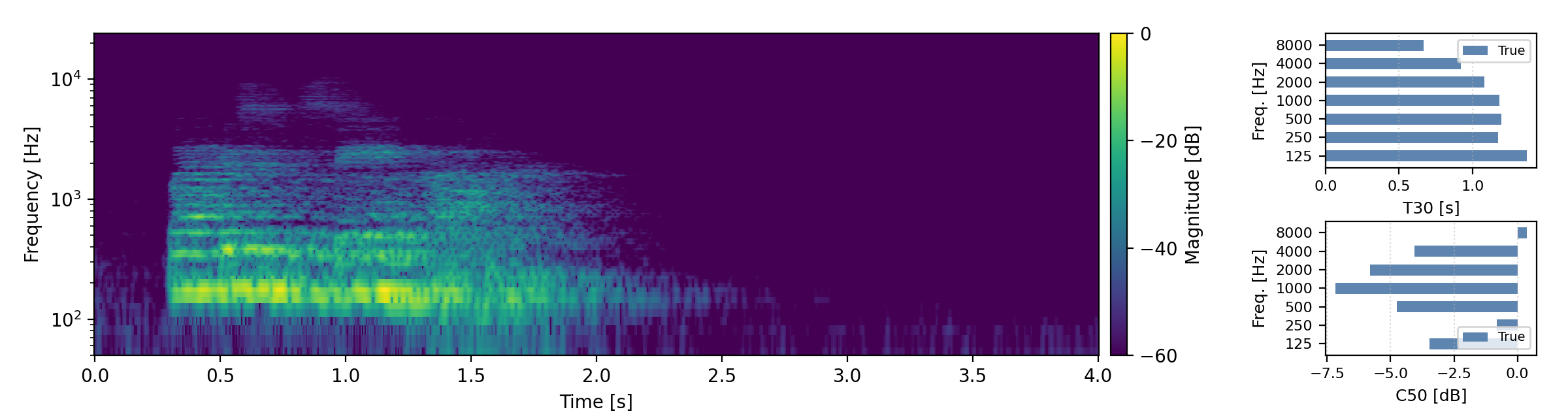
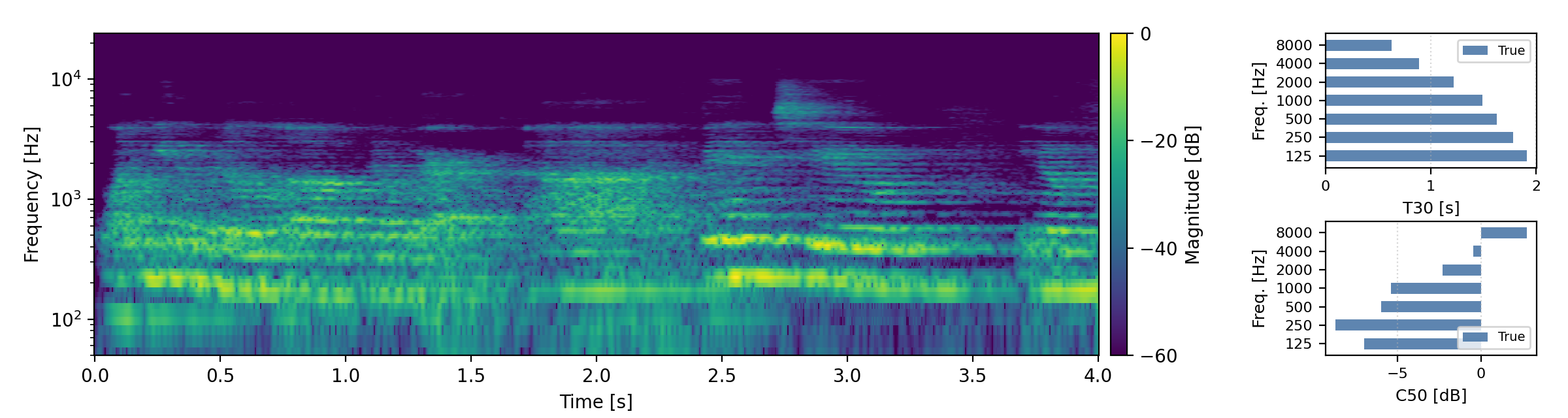
Below are randomly selected sound examples from the test data subset. For each example, we provide the reverberant and anechoic references, along with artificially reverberated signals generated using the proposed method and the baseline.
Short reverberation times (T60 < 0.3s)
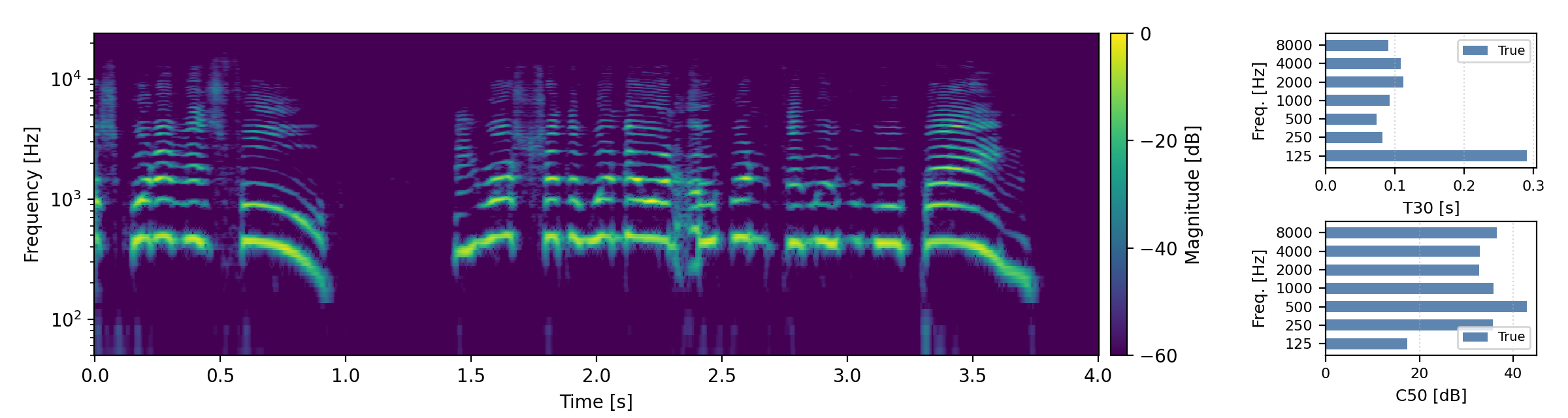
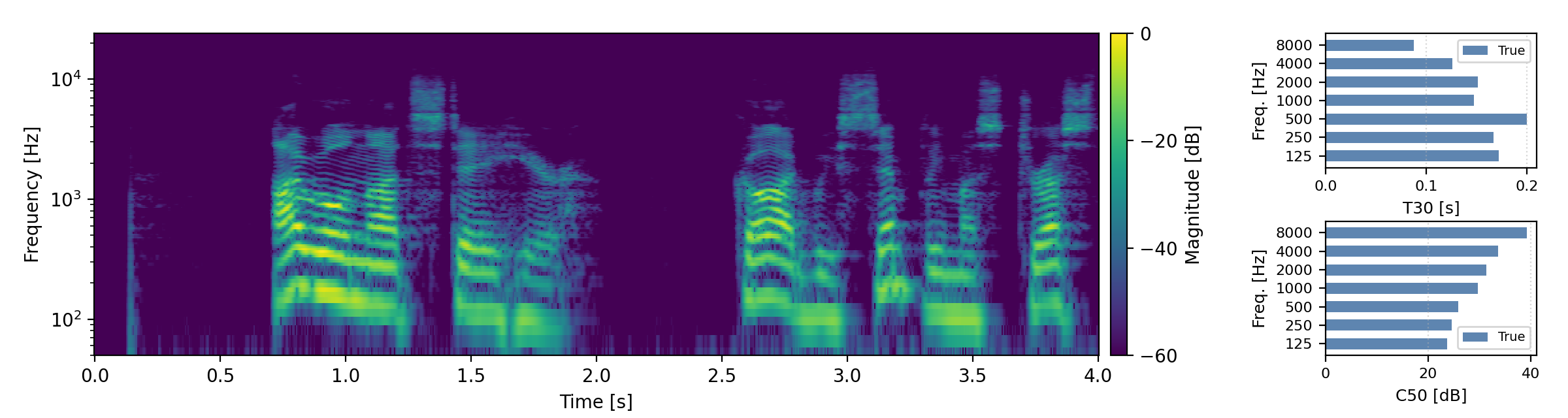
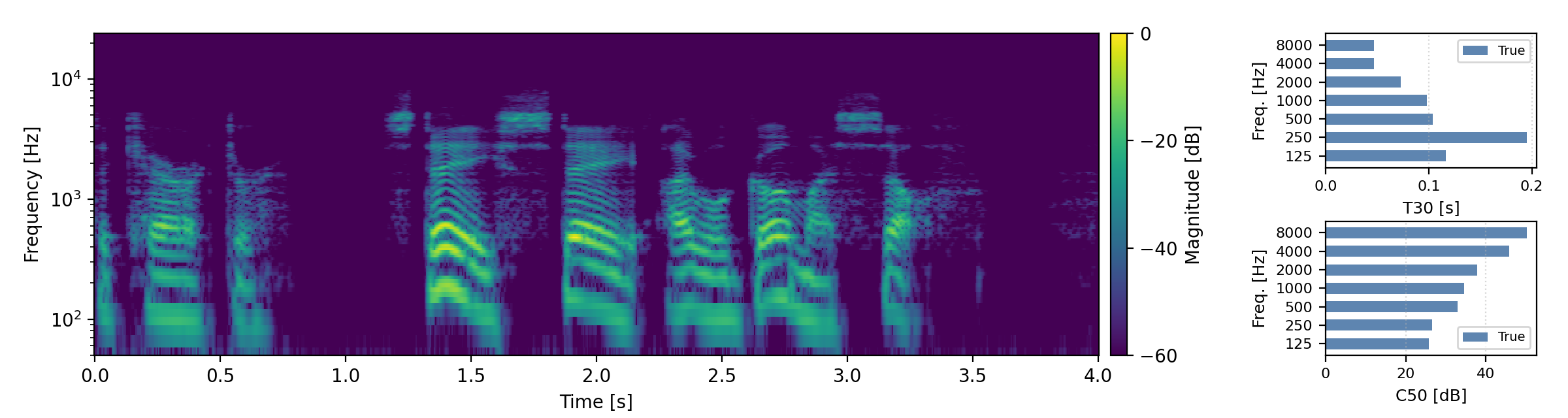
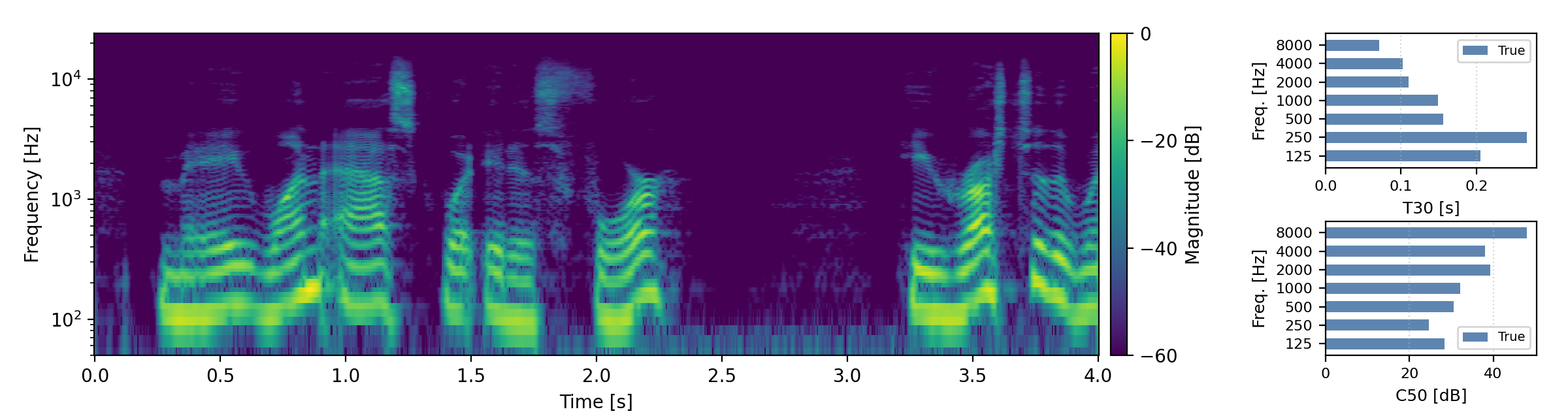
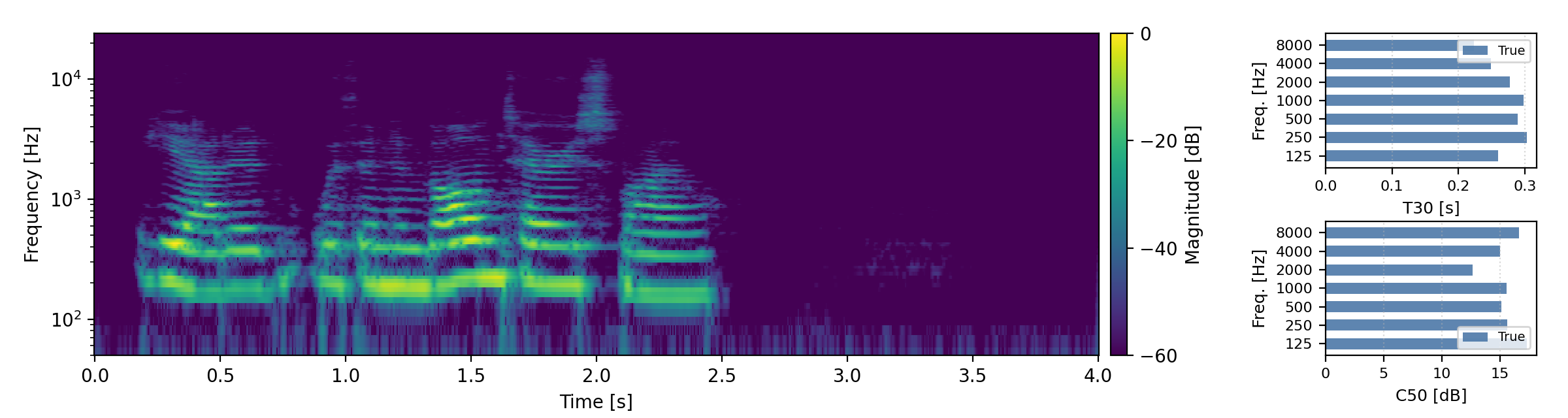
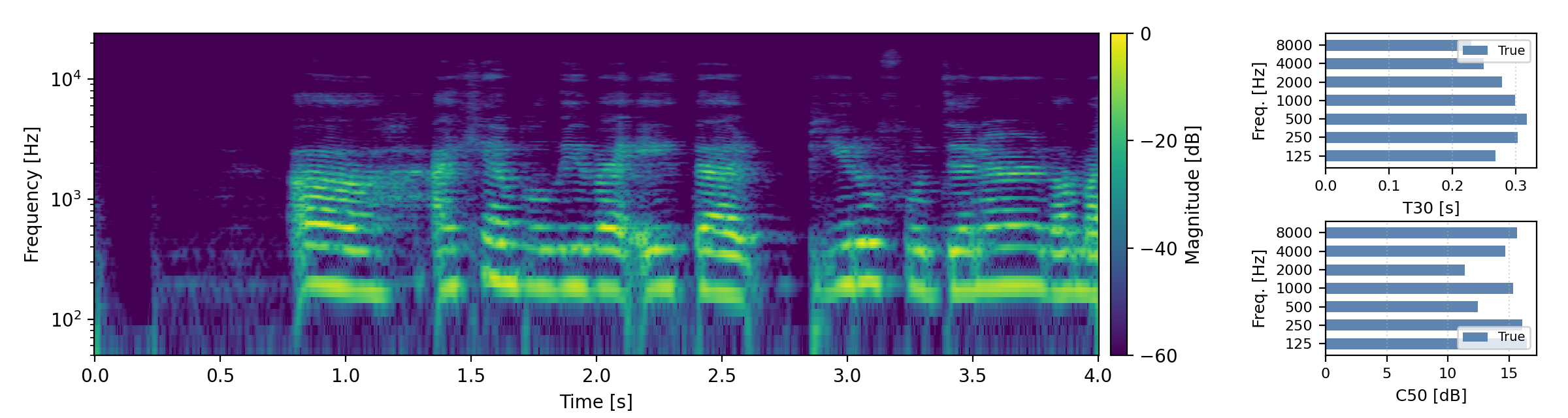
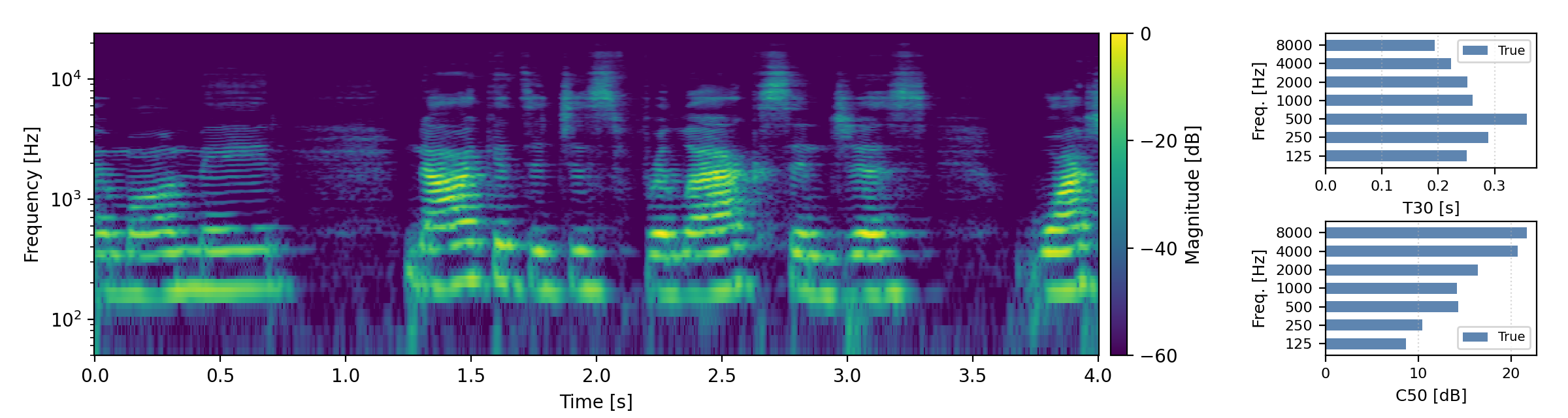
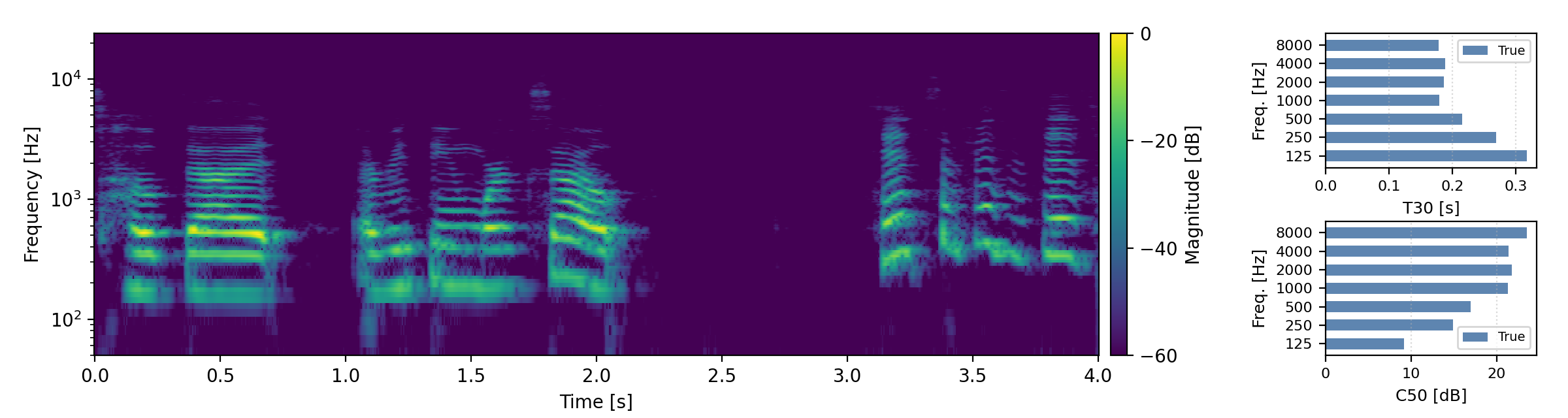
Medium reverberation times (0.3s < T60 < 0.8s)
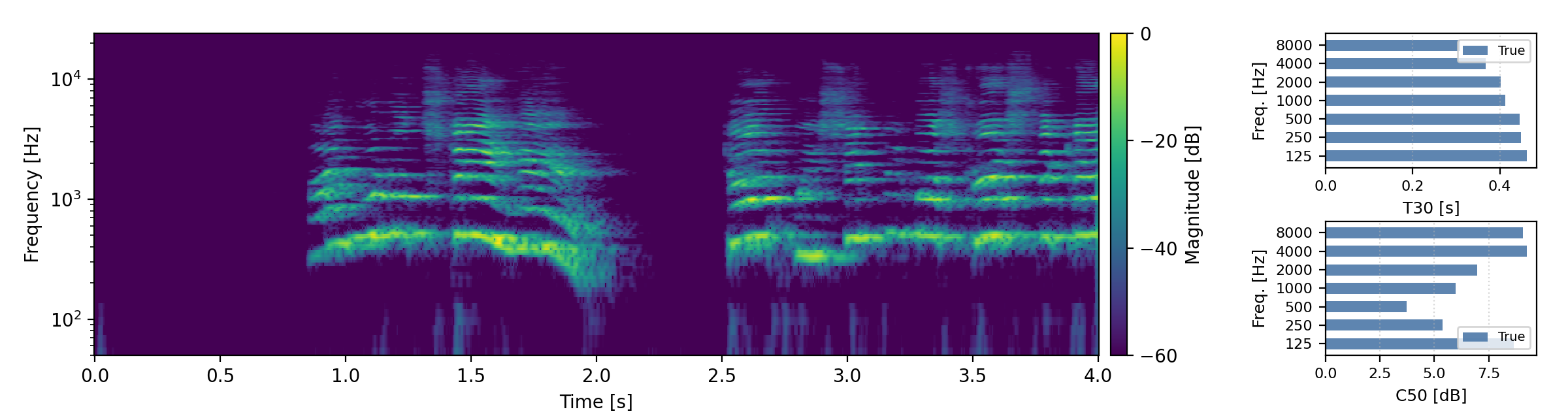
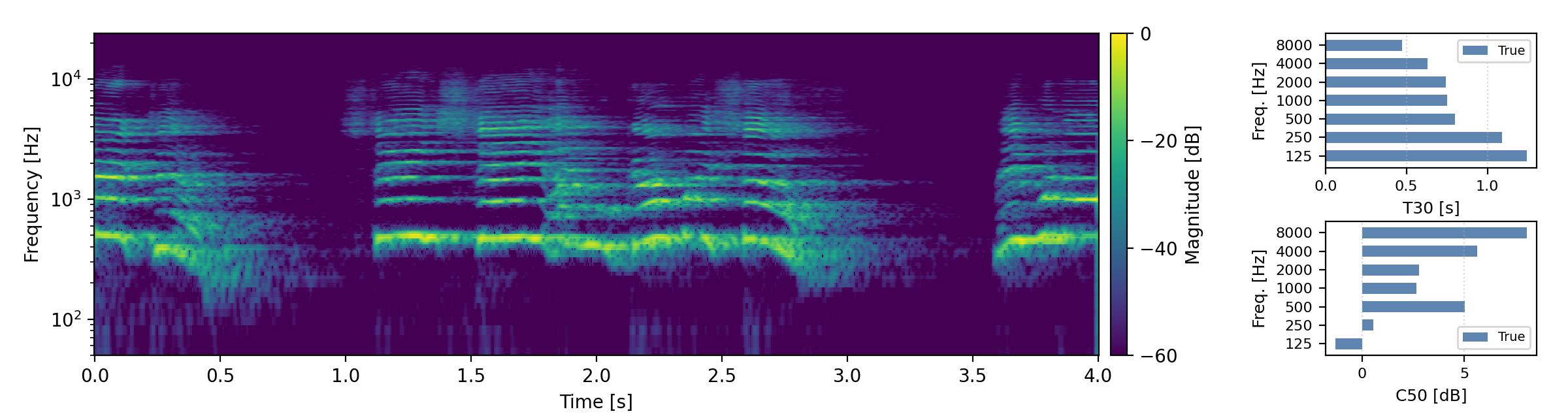
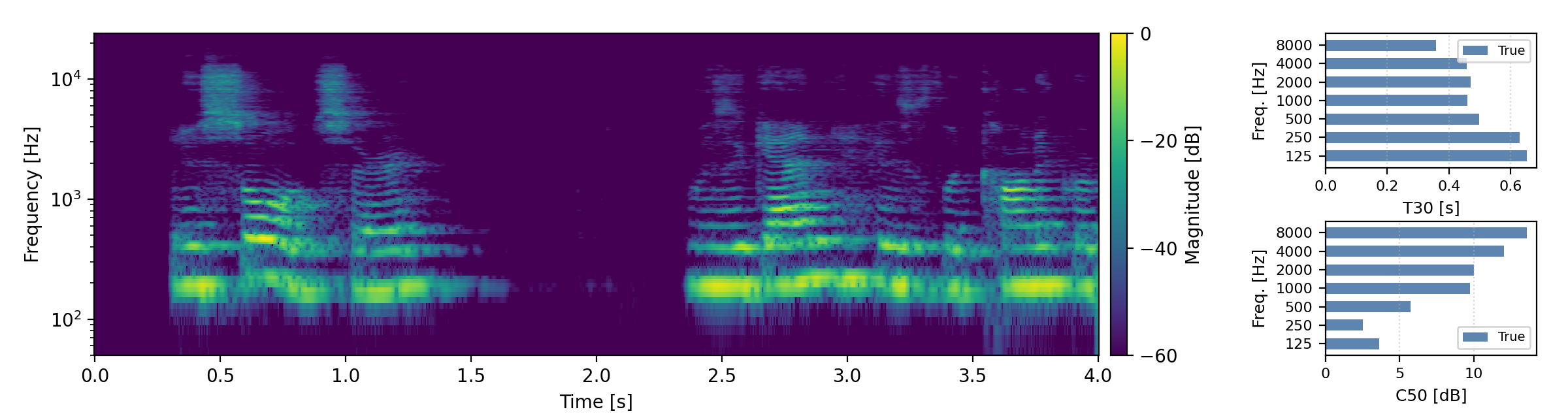
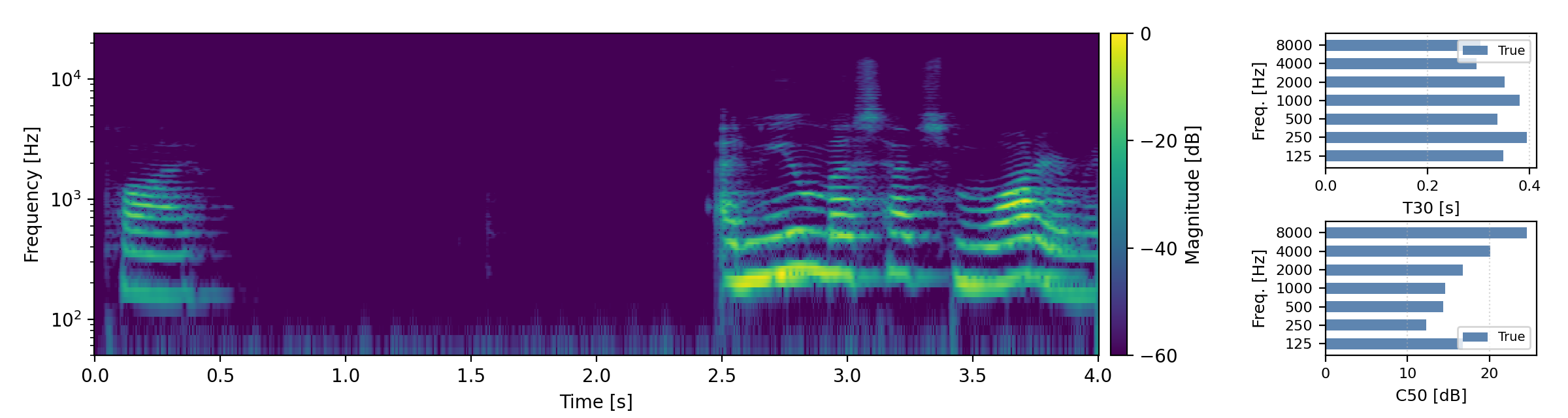
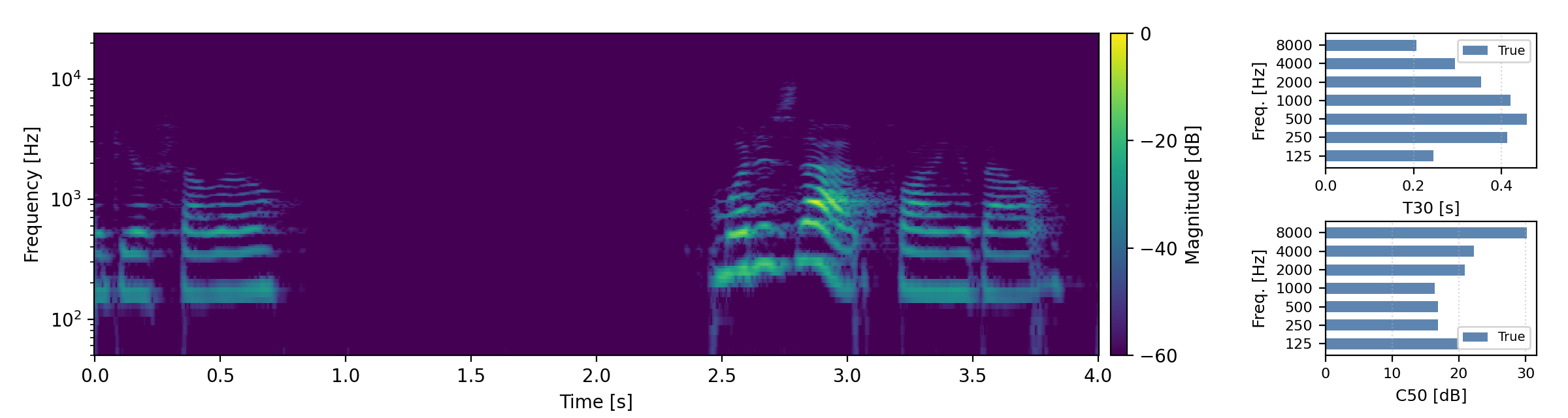
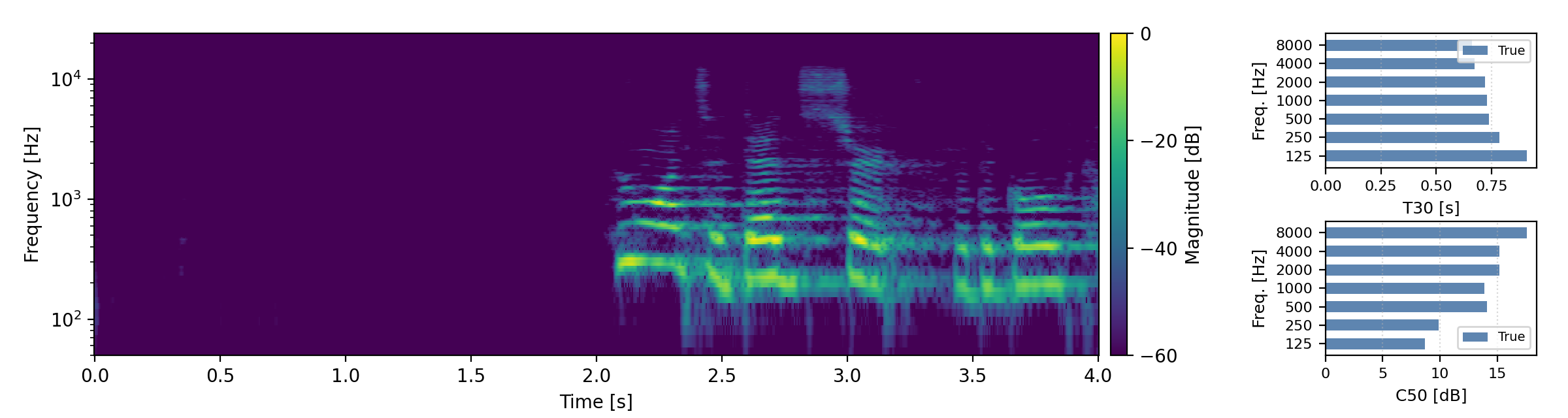
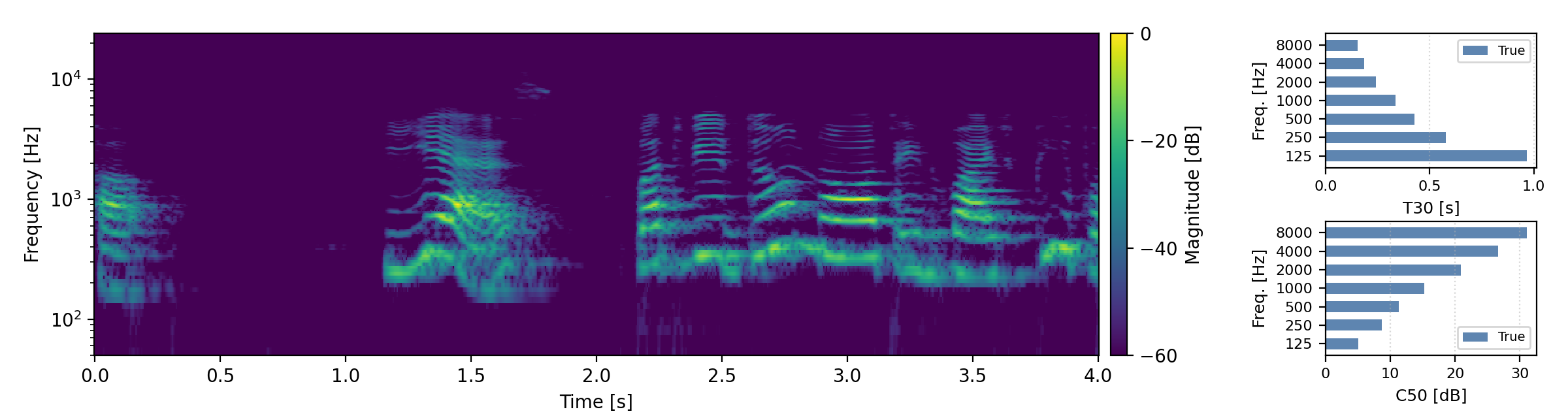
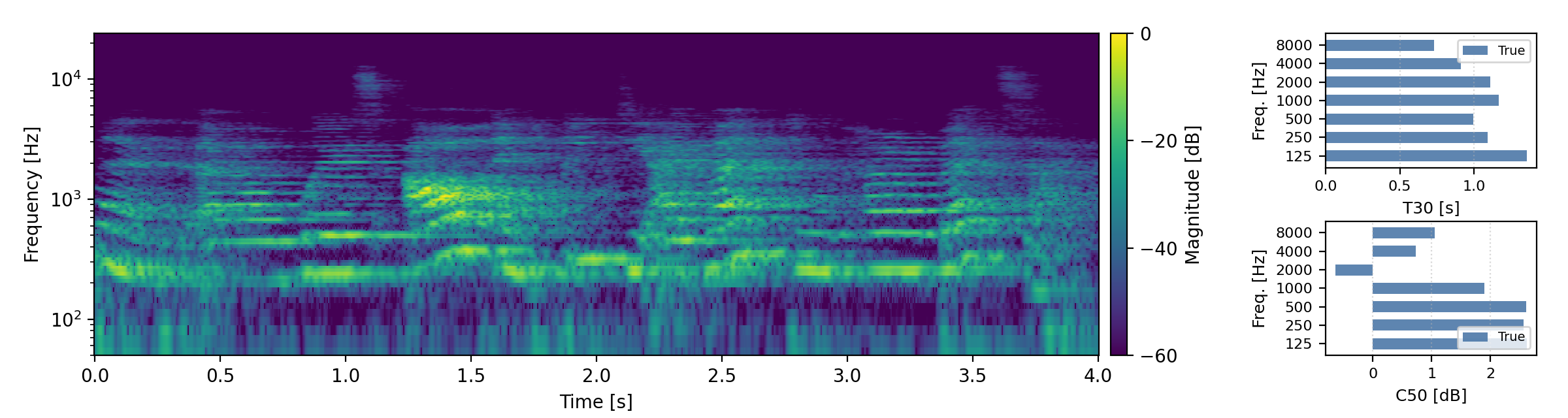
Long reverberation times (T60 > 0.8s)