

ACOUSTIC TELEPORTATION VIA DISENTANGLED NEURAL AUDIO CODEC REPRESENTATIONS
Philipp Grundhuber, Mhd Modar Halimeh, and Emanuel A. P. Habets
Published in the Proc. of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026.
Abstract
This paper presents an approach for acoustic teleportation by disentangling speech content from acoustic environment characteristics in neural audio codec representations. Acoustic teleportation transfers room characteristics between speech recordings while preserving content and speaker identity. We build upon previous work using the EnCodec architecture, achieving substantial objective quality improvements with non-intrusive ScoreQ scores of 3.03, compared to 2.44 for prior methods. Our training strategy incorporates five tasks: clean reconstruction, reverberated reconstruction, dereverberation, and two variants of acoustic teleportation. We demonstrate that temporal downsampling of the acoustic embedding significantly degrades performance, with even 2x downsampling resulting in a statistically significant reduction in quality. The learned acoustic embeddings exhibit strong correlations with RT60. Effective disentanglement is demonstrated using t-SNE clustering analysis, where acoustic embeddings cluster by room while speech embeddings cluster by speaker.
Acoustic Teleportation
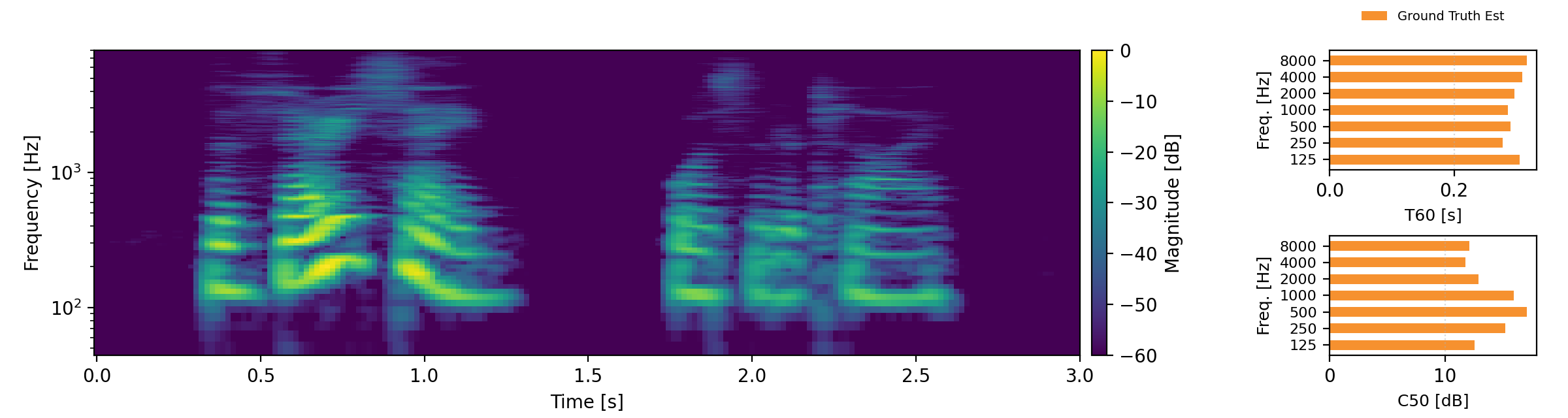
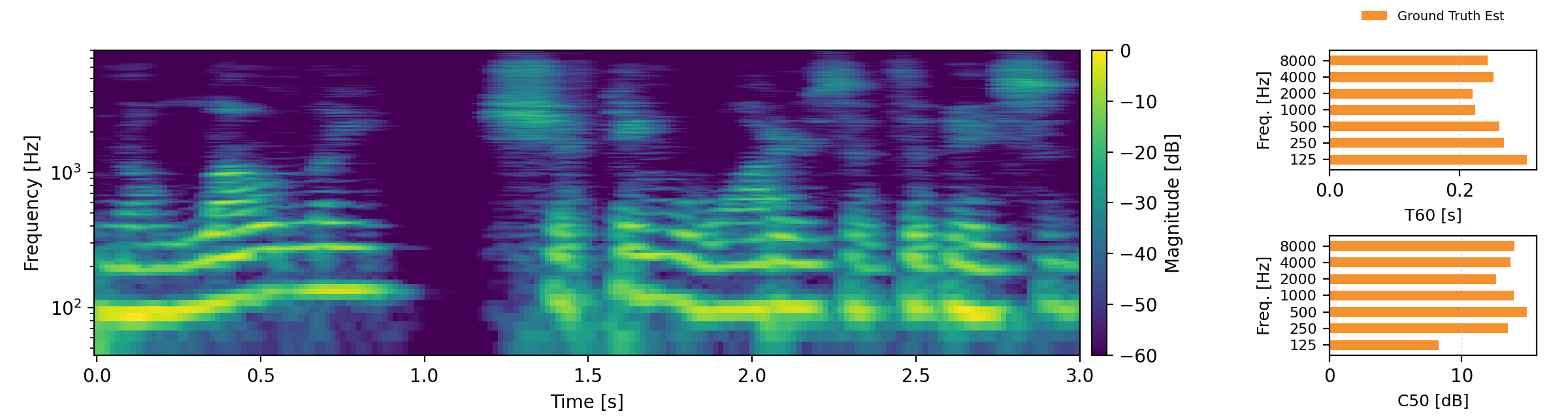
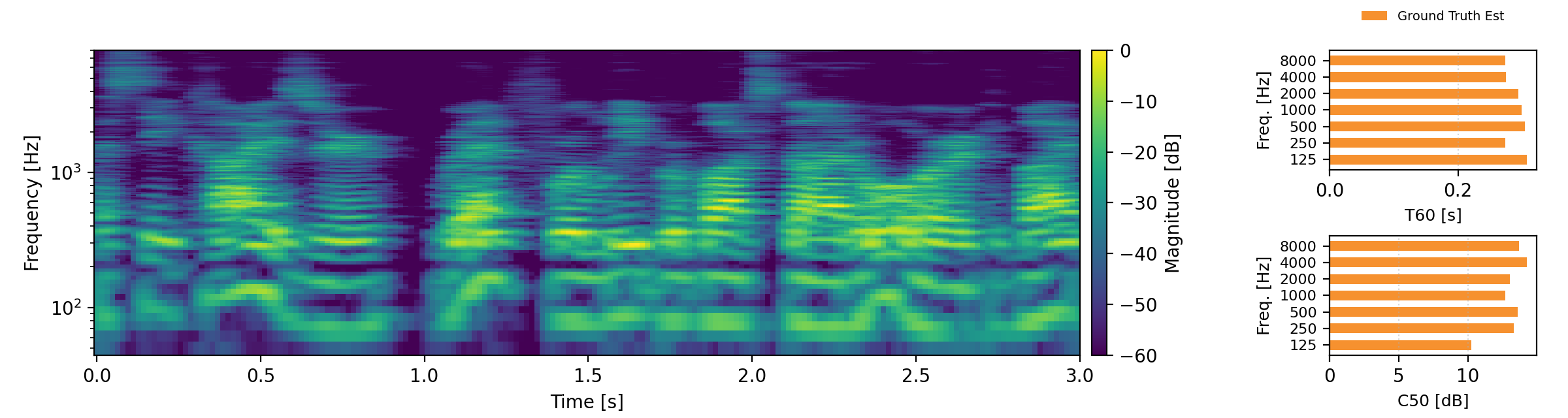
Acoustic teleportation extracts the acoustic characteristics (reverberation) from one recording and applies them to speech from a different environment. The examples below demonstrate swapping room acoustics between two speakers recorded in different rooms, preserving the original speech content while transferring the reverberation characteristics. For each example, we provide an estimate of T60 and C50 and compare these to the target C50 and T60 estimates. Omran examples are taken from here.
Proposed refers to our Acoustic Teleportation Model trained with Omran Task Set, No Quantization, No Downsampling.
Each demo contains:
- Input A & B: Two speech recordings in different acoustic environments
- Output with Speech A and Acoustics B: Takes the speech content from Input A and applies the room characteristics from Input B
- Output with Speech B and Acoustics A: Takes the speech content from Input B and applies the room characteristics from Input A
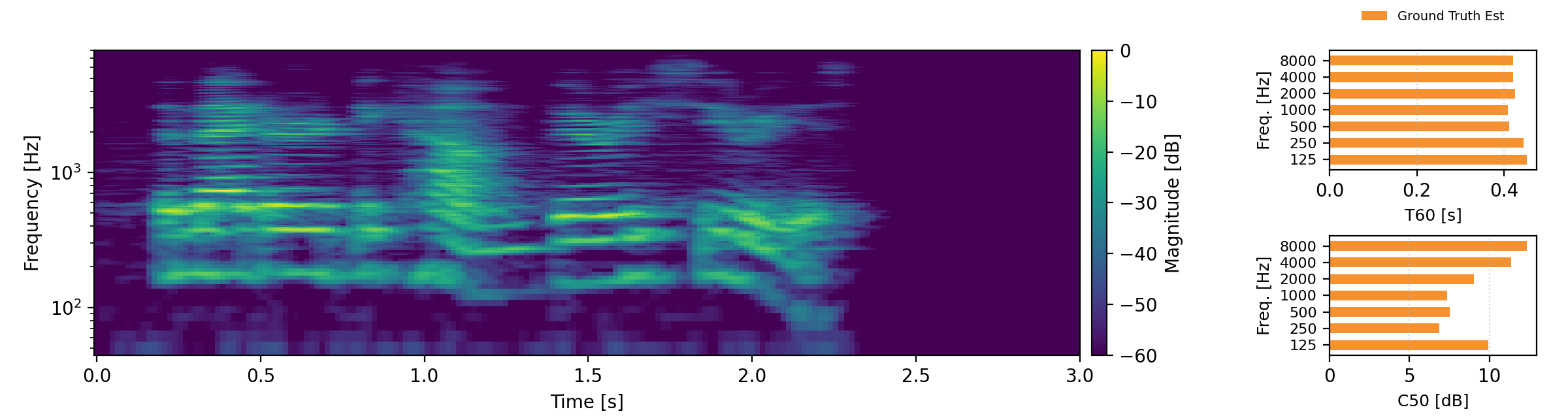
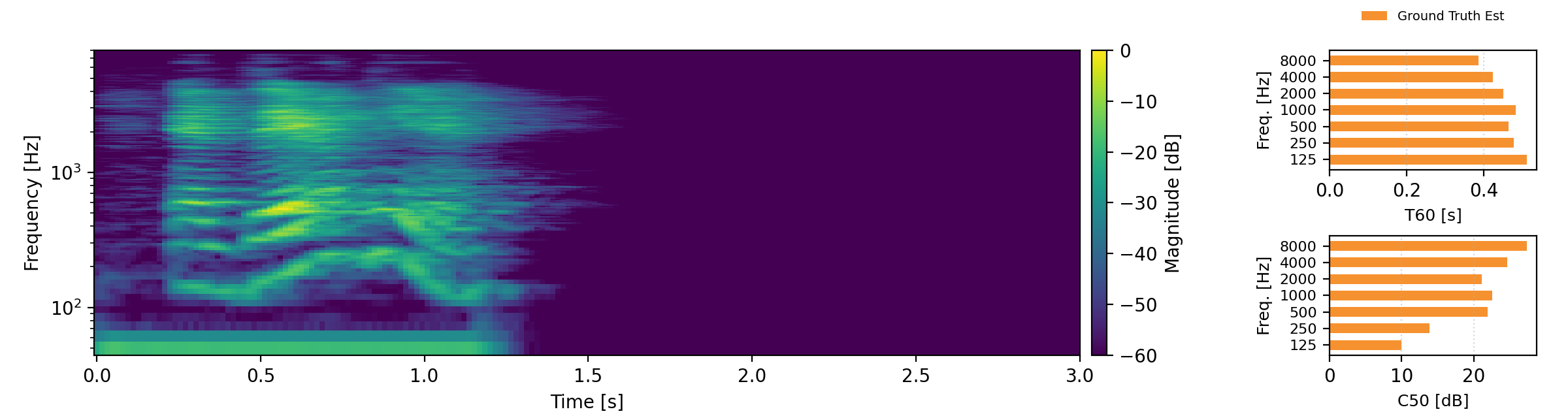
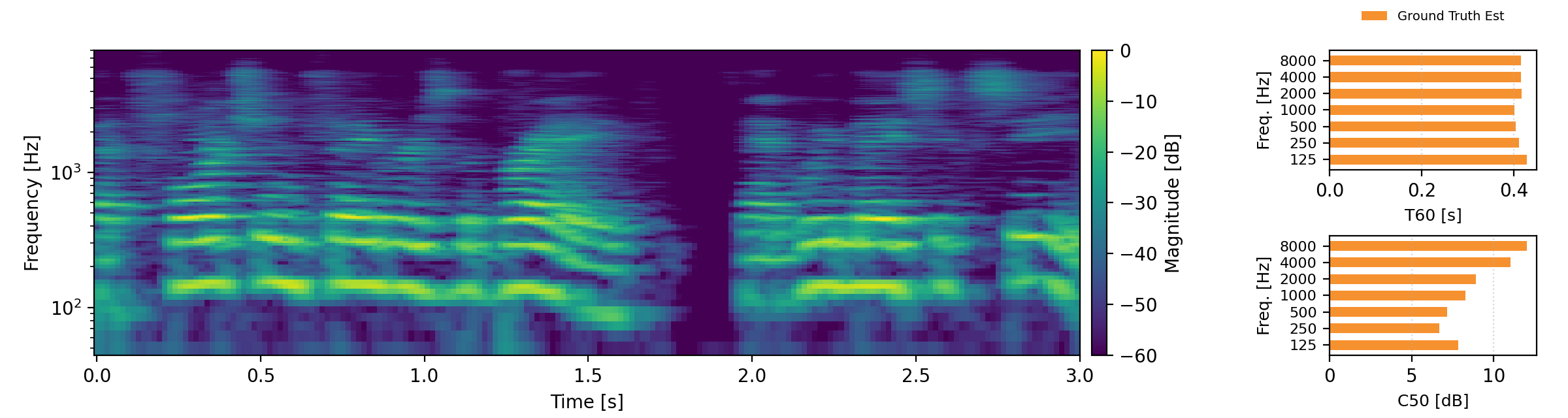
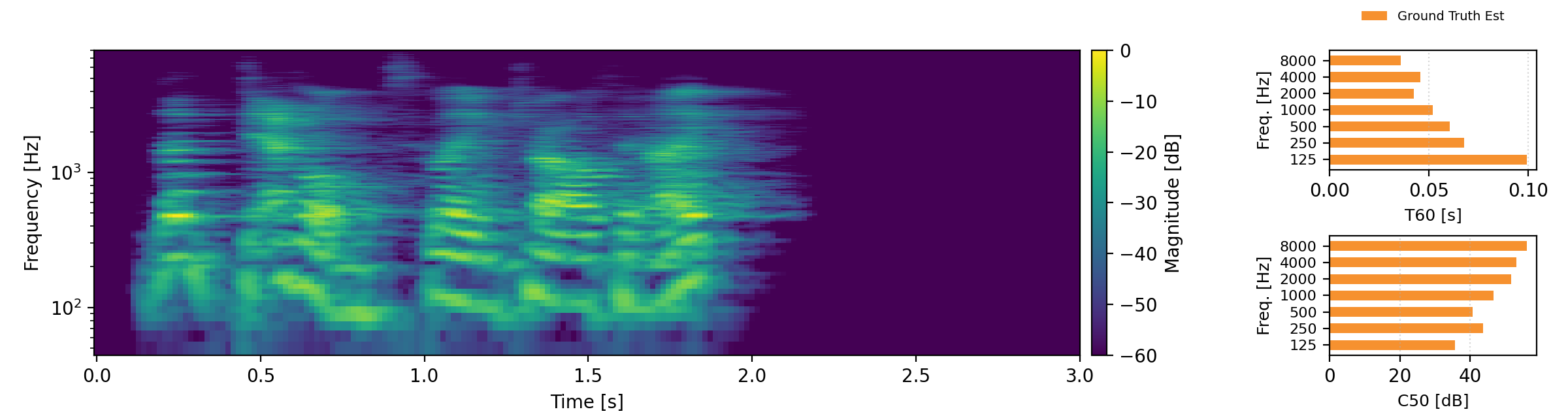
Reverb Reconstruction
The reverb reconstruction task demonstrates the model's ability to encode and accurately reconstruct reverberated speech. The player below shows multiple examples comparing the original reverberated inputs with reconstructions from both the Omran baseline method and our proposed approach.
