

Multi-Microphone Speaker Separation by Spatial Regions
J. Wechsler, S. R. Chetupalli, W. Mack and E. A. P. Habets
Published in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing, 2023.
Click here for the paper.
Abstract
We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
Example Audio
Below, we illustrate the performance with some examples, some of which show the success and some the failure of the source separation and/or the assignment of the signals to their source regions. We show both the performance of our baseline method (MC ConvTasNet [1]) and that of our proposed method. The examples constitute mixtures of three speakers according to the Libri3Mix [2] description that we spatialized. Furthermore, the examples are taken from all three test sets described in the paper.
Our proposed network SpaRSep is adapted from the AmbiSep architecture [3]. For our proposed method, we provide both the audio examples that emerged from training including permutation invariant training (PIT) [4] and those that the model output using our proposed region-based and region-preserving mapping. For all examples, we illustrate the distribution of sources and include the audio output of all methods for all three regions.
Note that all trainings converged to a region-preserving mapping and we align the evaluation to the main permutation. Therefore, there are also examples where the models trained with PIT show confounding between regions.
Example 1: Success of all methods
Libri3Mix ID 237-126133-0014_1320-122617-0034_8455-210777-0025

Fully concurrent activity of all three speakers (Matched Condition)
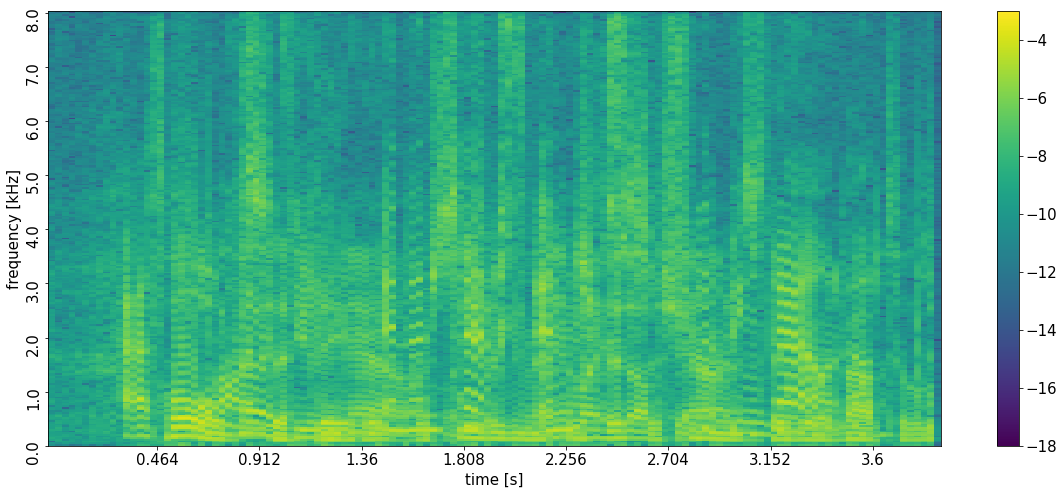
Fully concurrent activity of all three speakers with additive spatio-temporally white Gaussian noise (Unmatched Condition 1)
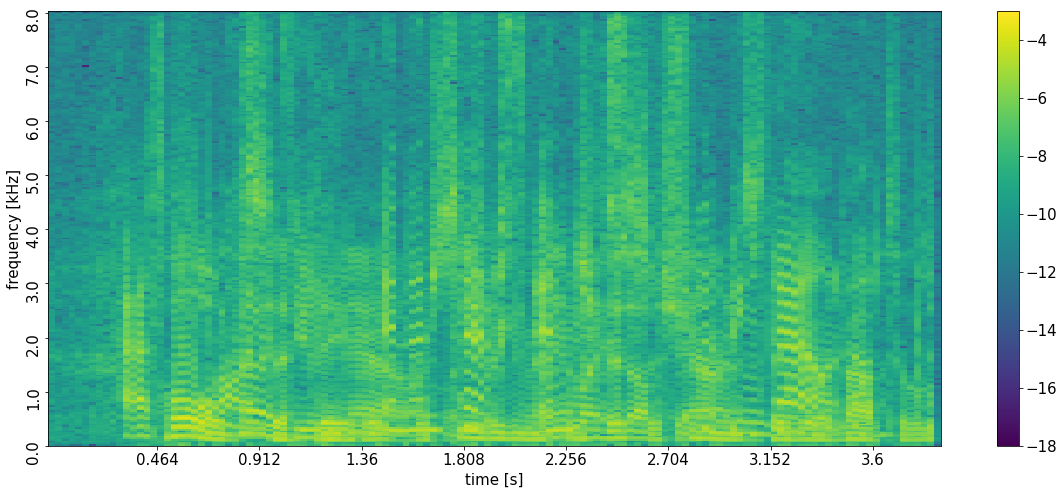
Partially overlapping speakers (Unmatched Condition 2)
Please note that the target signal for the individual regions is zero here for some periods. In the logarithmic representation of the PSD, we have chosen white areas for this.
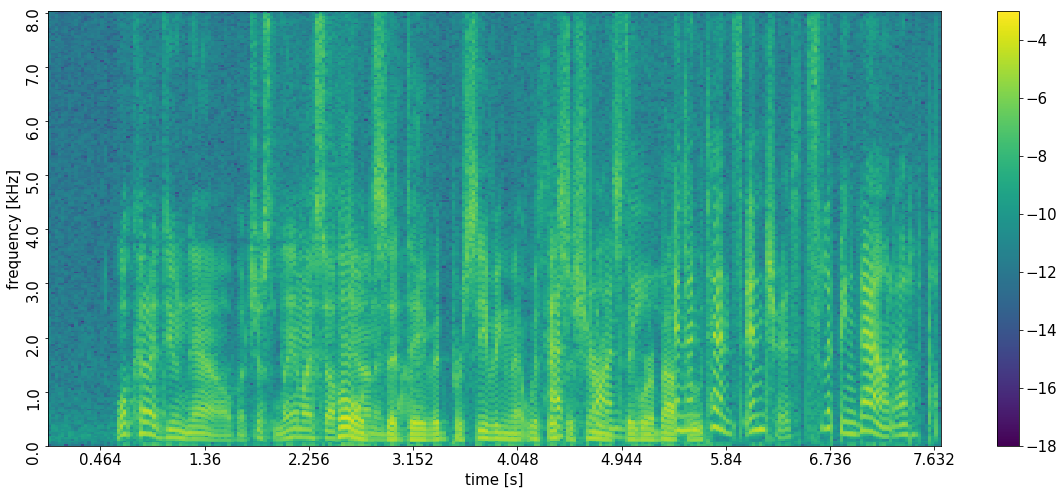
Example 2: Failure 1 - error in the assignment of signals to regions
Libri3Mix ID 1580-141084-0040_237-134493-0000_4992-41797-0002

The following is one of the rare examples (<0.5%) in which two of the methods deviate from their 'majority output permutation' while the signals themselves are separated "okay-ish". For MC ConvTasNet and SpaRSep with PIT, the assignment of the co-driver and backseats are confused, resulting in very low SI-SDR values. The confusion can be explained by the only slightly different dircetions-of-arrival of the signals from 'co-driver seat' (109º) and 'backseats' (114º). The SI-SDR values become comparable for all three methods when the signals are sorted according to the 'ground-truth permutation'.
Please note that there was no example in our test set(s) where all three methods failed simultaneously.
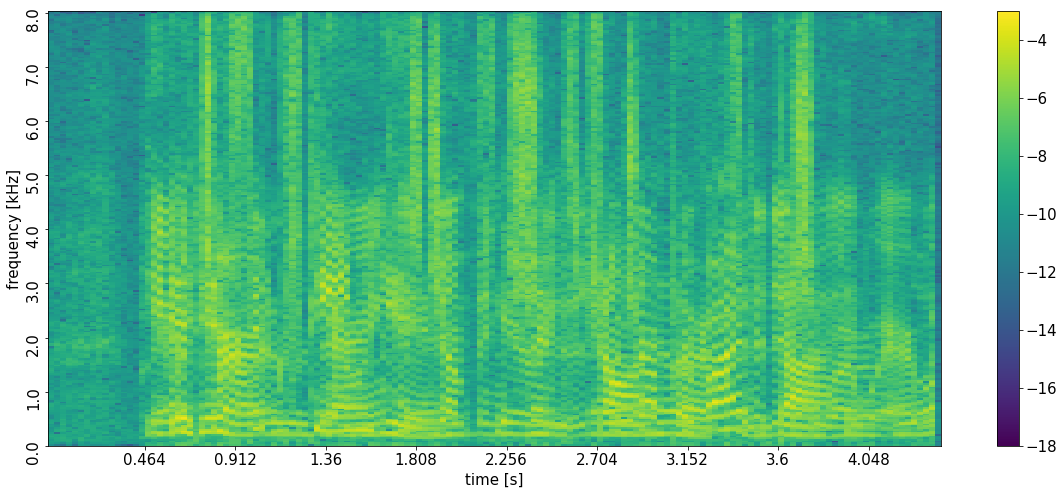
Example 3: Failure 2 - error in the separation
Libri3Mix ID 2830-3980-0047_6829-68769-0025_908-157963-0026

Complete separation failures did not occur based on the test set used. The following example shows how a weak source in the back seat, which has its DOA with respect to the array in common with the driver, is almost imperceptible at the network output.
Note that for our proposed method without PIT, for about 13 percent of the test samples the SI-SDR was more than 6 dB below the mean performance, i.e., below 10 dB for the front seats and below 5 dB for the rear seats. Of these "failures", for about 83 percent at least one of the sources was in one of the overlap regions. While this does not imply that there is actually a DOA overlap, it is nevertheless striking that in the remaining 37 percent of these "failures" mostly all sources were at least mediocrely separated and the SNR was never below 6.2 dB (front) and 3.9 dB (rear).
References
[1] Rongzhi Gu, Jian Wu, Shi-Xiong Zhang, Lianwu Chen, Yong Xu, Meng Yu, Dan Su, Yuexian Zou, and Dong Yu, “End-to-End Multi-Channel Speech Separation,” in arXiv: doi.org/10.48550/arXiv.1905.06286, 2019.
[2] Joris Cosentino, Manuel Pariente, Samuele Cornell, Antoine Deleforge, and Emmanuel Vincent, “LibriMix: An Open-Source Dataset for Generalizable Speech Separation,” in arXiv: doi.org/10.48550/ARXIV.2005.11262, 2020.
[3] Adrian Herzog, Srikanth Raj Chetupalli, and Emanuël A. P. Habets, “AmbiSep: Ambisonic-to-Ambisonic Reverberant Speech Separation Using Transformer Networks,” in Proc. Intl. W. Ac. Sig. Enh. (IWAENC), 2022.
[4] Dong Yu, Morten Kolbæk, Zheng-Hua Tan, and Jesper Jensen, “Permutation invariant training of deep models for speaker-independent multi-talker speech separation,” in Proc. IEEE Intl. Conf. on Ac., Sp. and Sig. Proc. (ICASSP), 2017, pp. 241–245.