

Explainable Acoustic Scene Classification: Making Decisions Audible
H. Nazim Bicer, Philipp Götz, Cagdas Tuna, and Emanuël A. P. Habets
International Workshop on Acoustic Signal Enhancement (IWAENC) 2022
Abstract
This study presents a sonification method that provides audible explanations to improve the transparency of the decision-making processes of convolutional neural networks designed for acoustic scene classification (ASC). First, a deep neural network (DNN) based on the ResNet architecture [1] is proposed. Secondly, Grad-CAM [2] and guided backpropagation [3] images are computed for a given input signal. These images are then used to produce frequency-selective filters that retain signal components in the input that contribute to the decision of the trained DNN. The test results demonstrate that the proposed model outperforms two baseline models. The reconstructed audio waveform is interpretable by the human ear, serving as a valuable tool to examine and possibly improve ASC models.
Sonification Examples
Below are five listening examples from different acoustic scenes. For each scene, the input signal and the two sonification outputs, based on Grad-CAM and guided backpropagation, are presented.
Acoustic scene: Beach
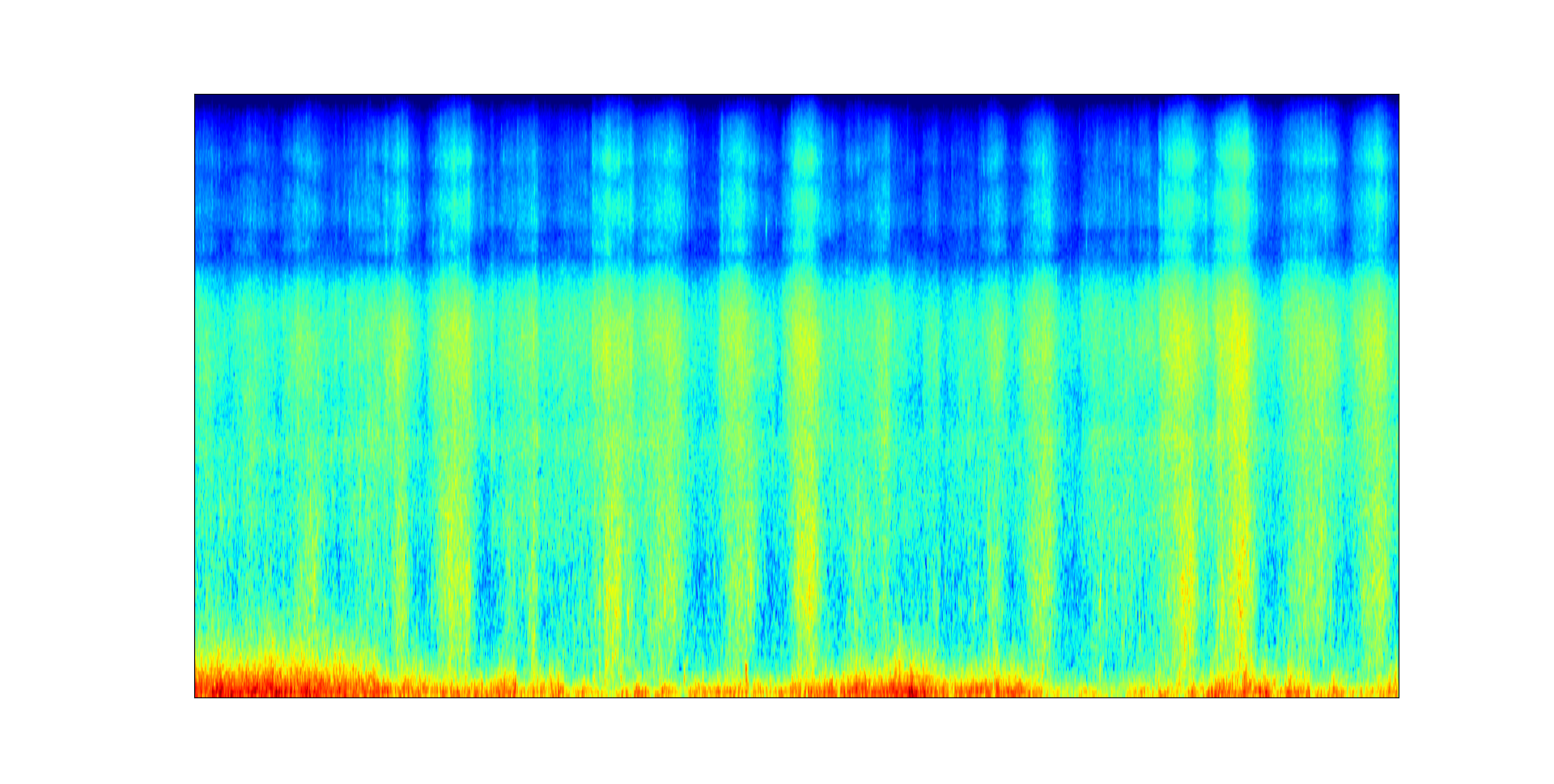
Acoustic scene: Forest path
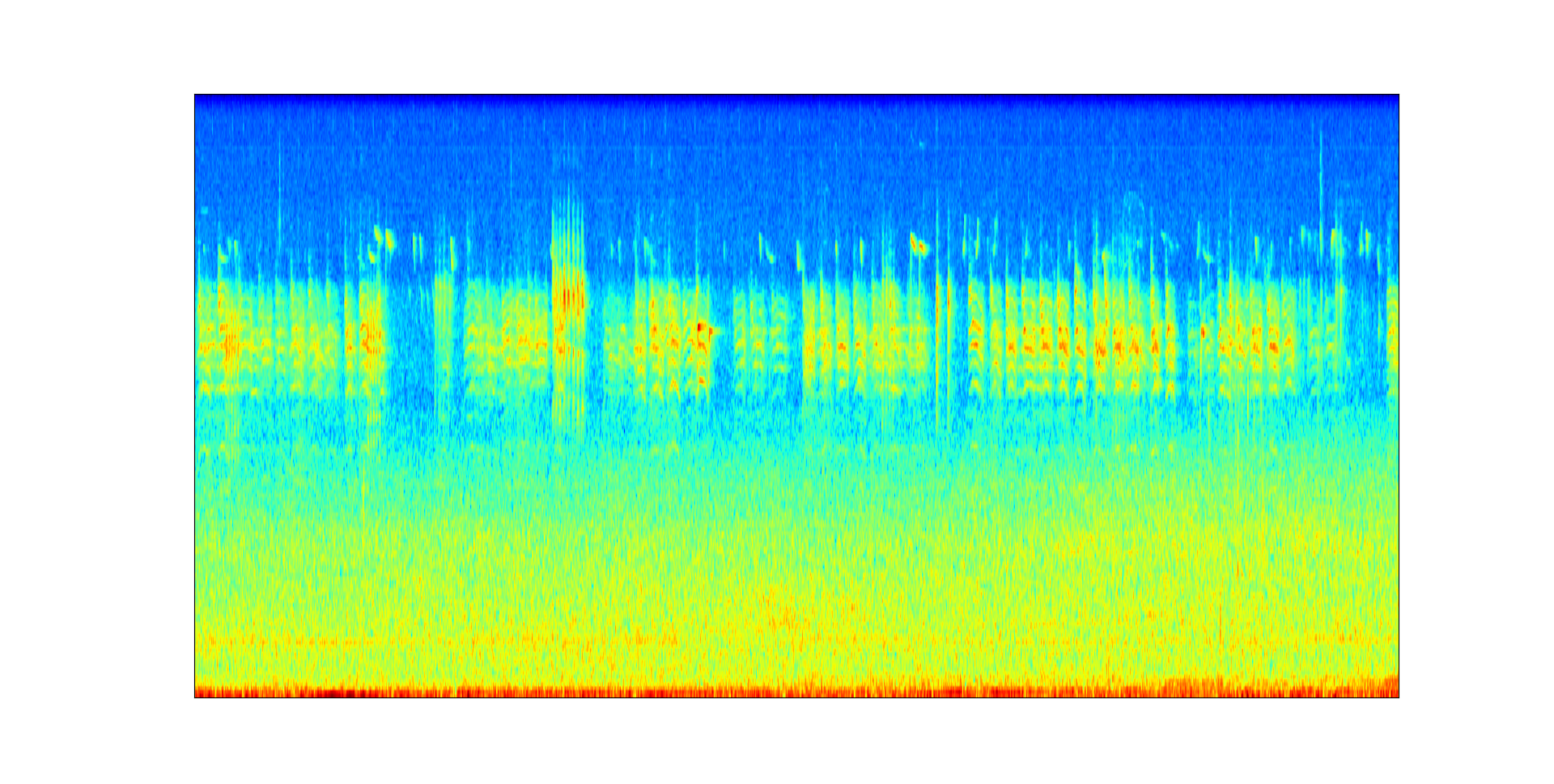
Acoustic scene: Car
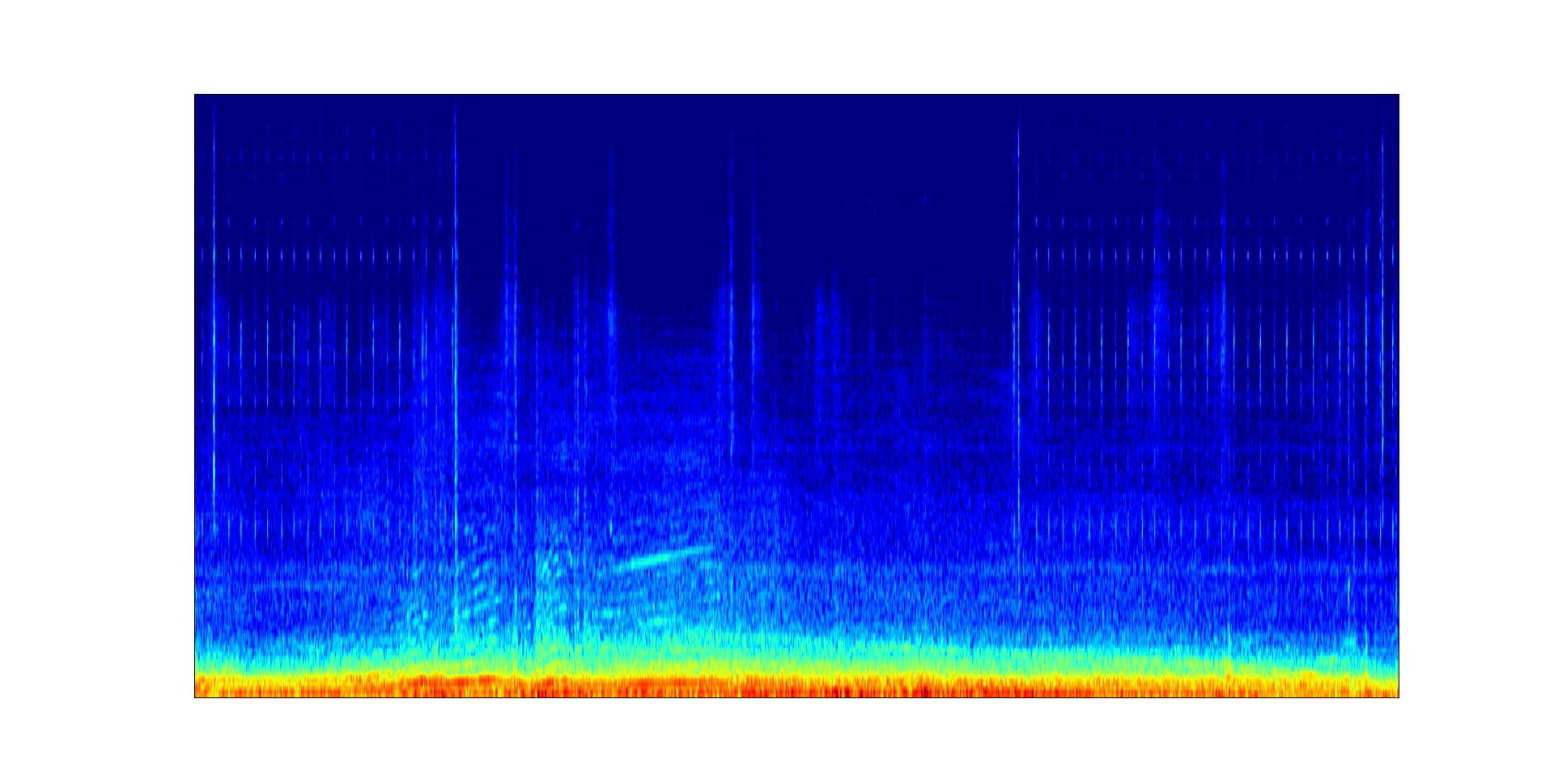
Acoustic scene: Library

Acoustic scene: Bus
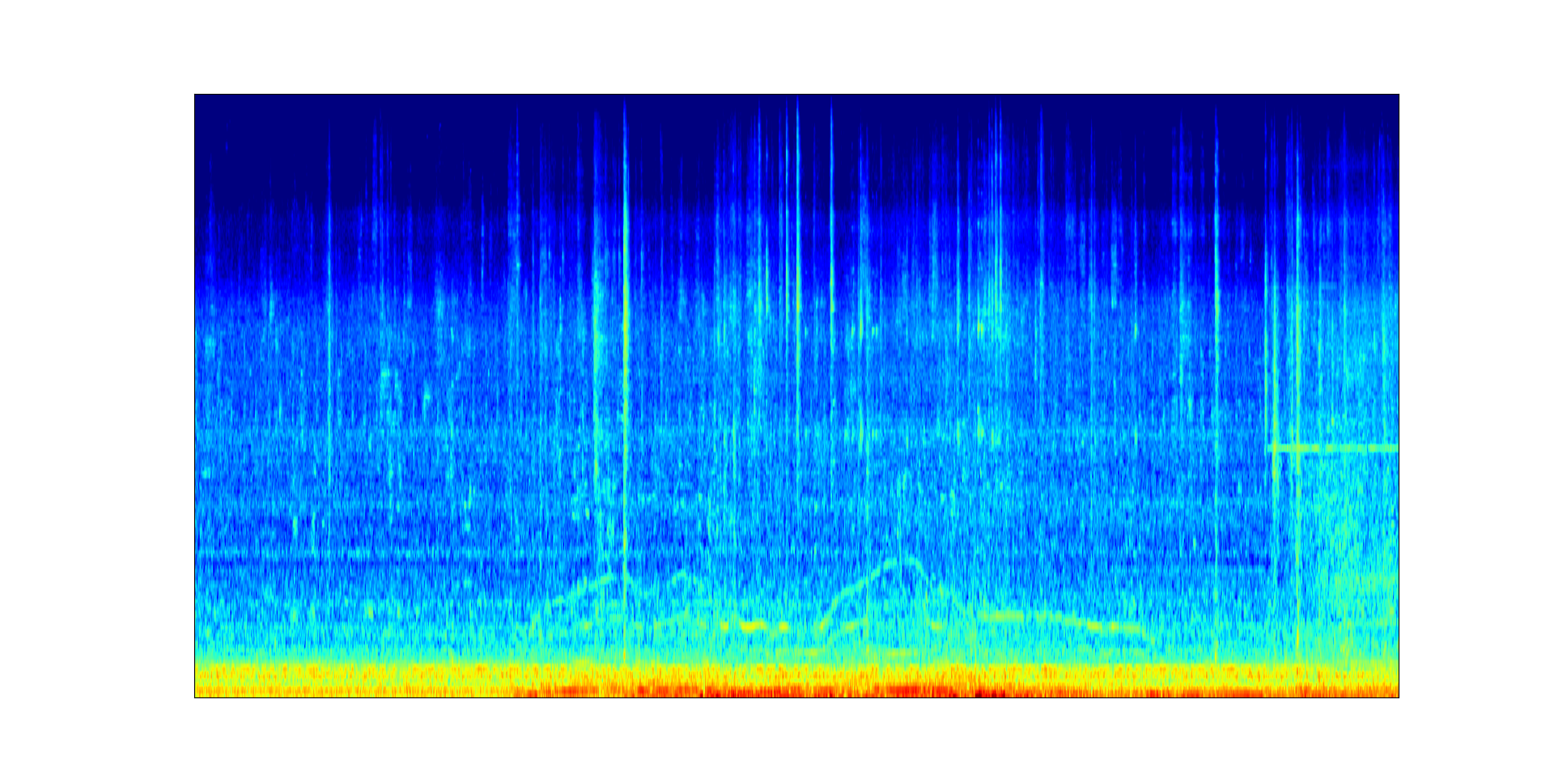
References
[1] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[2] Selvaraju, Ramprasaath R., et al. "Grad-CAM: Visual explanations from deep networks via gradient-based localization." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[3] Springenberg, Jost Tobias, et al. "Striving for simplicity: The all convolutional net." arXiv preprint arXiv:1412.6806 (2014).