

Informed Source Extraction With Application to Acoustic Echo Reduction
M. Elminshawi, W. Mack, and E. A. P. Habets
ITG Conference on Speech Communication 2021.
Abstract
Informed speaker extraction aims to extract a target speech signal from a mixture of sources given prior knowledge about the desired speaker. Recent deep learning-based methods leverage a speaker discriminative model that maps a reference snippet uttered by the target speaker into a single embedding vector that encapsulates the characteristics of the target speaker. However, such modeling deliberately neglects the time-varying properties of the reference signal. In this work, we assume that a reference signal is available that is temporally correlated with the target signal. To take this correlation into account, we propose a time-varying source discriminative model that captures the temporal dynamics of the reference signal. We also show that existing methods and the proposed method can be generalized to non-speech sources as well. Experimental results demonstrate that the proposed method significantly improves the extraction performance when applied in an acoustic echo reduction scenario.
Pipeline
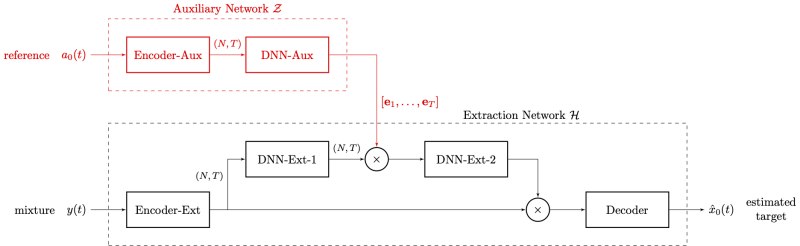
Audio Example 1: Speaker vs. Speaker
References
[1] M. Delcroix, T. Ochiai, K. Zmolikova, K. Kinoshita, N. Tawara, T. Nakatani, and S. Araki, “Improving speaker discrimination of target speech extraction with time-domain speakerbeam,” in Proc. IEEE Intl. Conf. on Ac., Sp. and Sig. Proc. (ICASSP), 2020, pp. 691–695.
[2] H. Zhang and D. L. Wang, “Deep learning for acoustic echo cancellation in noisy and double-talk scenarios,” in Proc. Interspeech Conf., 2018, pp. 3239–3243.