

Generating coherence-constrained multisensor signals using balanced mixing and spectrally smooth filters
D. Mirabilii, S. Schlecht and E. A. P. Habets
The Journal of the Acoustical Society of America, Vol. 149, Issue 3, pp. 1425-1433, Mar. 2021, doi:10.1121/10.0003565
Abstract
The spatial properties of a noise field can be described by a spatial coherence function. Synthetic multichannel noise signals exhibiting a specific spatial coherence can be generated by properly mixing a set of uncorrelated, possibly non-stationary, signals. The mixing matrix can be obtained by decomposing the spatial coherence matrix. As proposed in [1], the factorization can be performed by means of a Choleski or an eigenvalue decomposition. In this work, the limitations of these two methods are discussed and addressed. In particular, specific properties of the mixing matrix are analyzed, namely the spectral smoothness and the mix balance. The first quantifies the mixing matrix-filters variation across frequency and the second quantifies the amount of input signals that contribute to each output signal. Three methods based on the unitary Procrustes solution are proposed to enhance the spectral smoothness, the mix balance and both properties jointly. A performance evaluation confirms the improvements of the mixing matrix in terms of objective measures. Further, the evaluation results show that the error between the target and the generated coherence is lowered by increasing the spectral smoothness of the mixing matrix.
Audio Examples
In the following examples, we present the output signals obtained by mixing mutually uncorrelated input signals. The input is generated by splitting a mono signal into consecutive audio chunks, one for each channel. The input signals are then filtered and summed by means of a mixing matrix to obtain output signals exhibiting a target spatial coherence. The mixing matrix is obtained by decomposing the target coherence matrix, which can be chosen arbitrarily. This simulates a desired spatial response, given the number and the positions of the microphones.
Optionally, the smoothness and the balance can be enhanced by the proposed methods.
- Unprocessed: mono signal from which uncorrelated audio chunks are extracted
- CHD [1]: baseline method, Choleski decomposition.
- EVD [1]: baseline method, eigenvalue decomposition.
- CHD balanced: proposed method, Choleski decomposition with enhanced mix balance.
- EVD balanced: proposed method, eigenvalue decomposition with enhanced mix balance.
- CHD balanced and smooth: proposed method, Choleski decomposition with enhanced mix balance and spectral smoothness
- EVD balanced and smooth: proposed method, eigenvalue decomposition with enhanced mix balance and spectral smoothness.
Example 1: Applause
We simulated the spatial response of people applauding around a microphone array in a closed room. The microphone positions were such to obtain a non-uniform linear array of 4 microphones with inter-sensor distances of 2,3,4 cm. The target spatial coherence was a spherically isotropic (3D diffuse) model. The mono signal contained only two people clapping. The objective was to obtain output signals resembling an applause of several people.
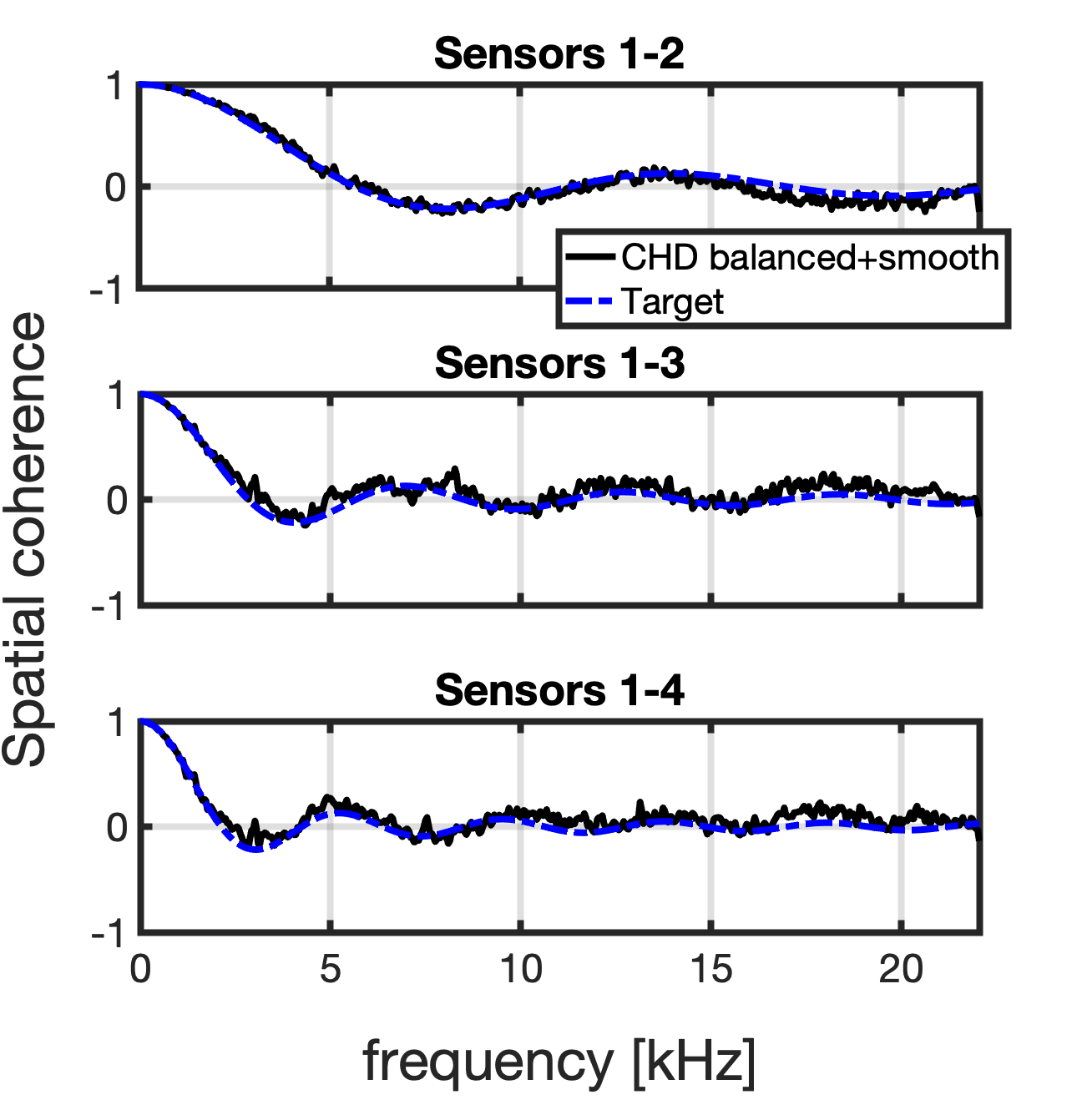
The baseline approach was given by the Choleski decomposition (CHD). Due to the fact that the Choleski solution yields a triangle matrix, the mix is unbalanced. For example, the first output channel is the exact copy of the first input signal, while the fourth output channel contains all the four input signals.
In addition to obtaining an accurate desired spatial response, we increased the mix balance: each output channel contains similar contributions of the input signals (CHD balanced). However, this results in mixing matrices that are dissimilar traversing the frequencies. This causes significant distortions. Hence, we induced spectral smoothness: we minimised the variation between mixing matrices across frequency while preserving the mix balance (CHD balanced and smooth). This way, the output signals are perceptually more plausible.
Following, the comparison between the (pair-wise) target spatial coherence (in dashed blue) and the spatial coherence measured from the output signals exploiting the proposed method (in solid black) from the example above.
Example 2: Rain
We simulated the spatial response of rain recorded by a microphone array. The microphone positions were such to obtain a uniform circular array of 4 microphones with a radius of 1 cm. The target spatial coherence was a cylindrical isotropic (2D diffuse) model. The mono signal consisted of a single-channel recording of light rain. The objective was to obtain output signals resembling a medium-strong rain.
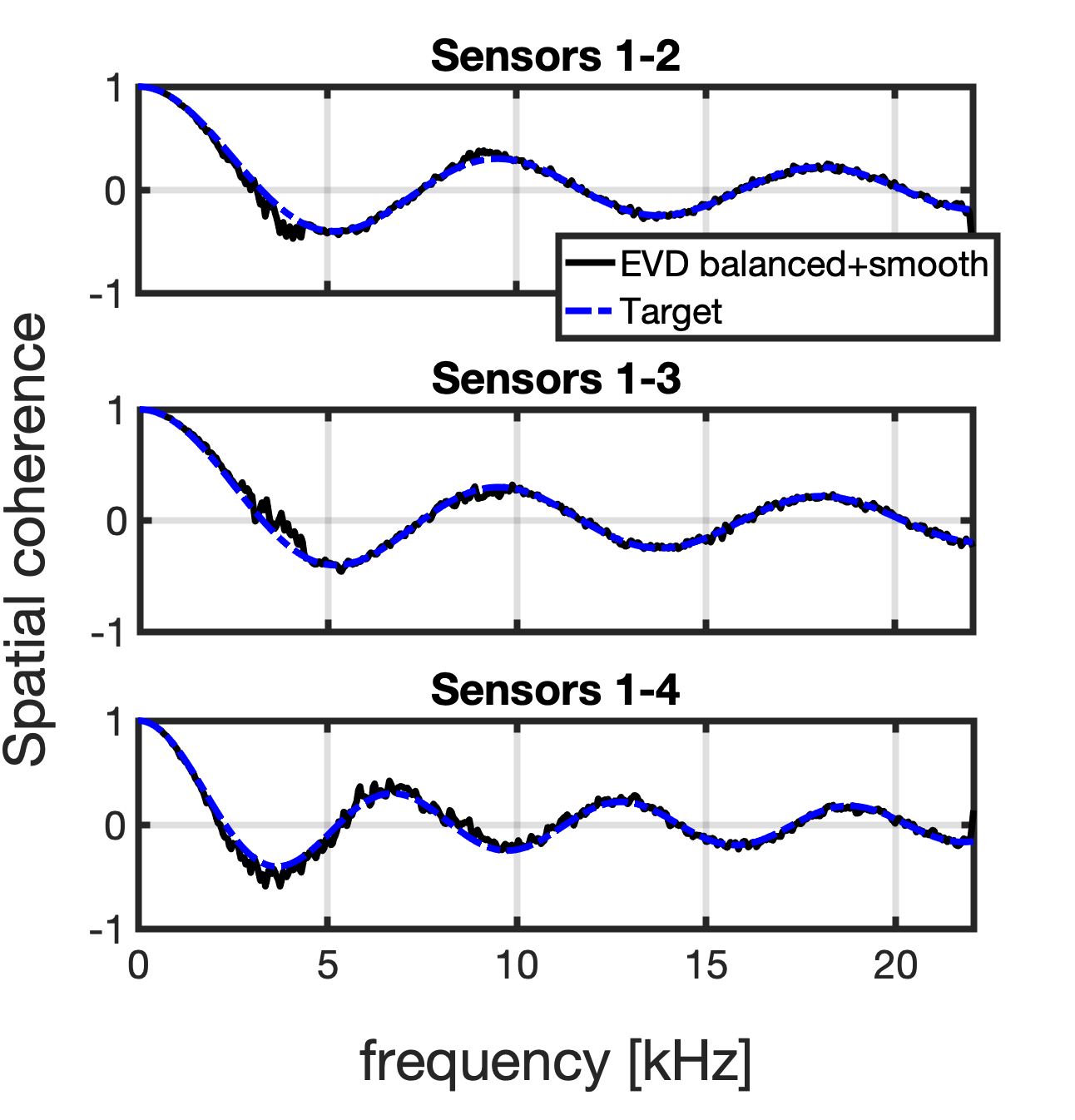
The baseline approach was given by the eigenvalue decomposition (EVD). Although this solution yields a well-balanced mix, it is not spectrally smooth. This results in significant audio artifacts in the output signals, especially during transients.
We also included the output signals of the EVD to which we induced balance (EVD balanced). Significant distortions are present similarly to the previous example. We then induced spectral smoothness while preserving the balance using the preferred method (EVD balanced and smooth). Once again, the last method reduced the distortions while yielding a balanced mix.
Following, the comparison between the (pair-wise) target spatial coherence (in dashed blue) and the spatial coherence measured from the output signals exploiting the proposed method (in solid black) from the example above.
References
- E.A.P. Habets, I. Cohen and S. Gannot, 'Generating nonstationary multisensor signals under a spatial coherence constraint,' Journal of the Acoustical Society of America, Vol. 124, Issue 5, pp. 2911-2917, Nov. 2008. Code