Demo for PhD defense
Description
The following three dereverberation algorithms are the outcome of my PhD thesis "Speech dereverberation in noisy environments using time-frequency domain signal models":
- Single-channel Wiener filter using relative convolutive transfer functions [1]
- Multichannel Wiener filter using a blocking-based reverberation PSD estimator with bias compensation [2]
- Multichannel linear prediction based dereverberation and noise reduction (dual-Kalman) [3]
[1] Braun, S., Schwartz, B., Gannot, S., and Habets, E. A. P., Late reverberation PSD estimation for single-channel dereverberation using relative convolutive transfer functions, In International Workshop on Acoustic Signal Enhancement (IWAENC), 2016.
[2] Braun, S., and Kuklasinski, A., Schwartz, O., Thiergart, O., Habets, E. A. P., Gannot, S., Doclo, S., and Jensen, J., "Evaluation and comparison of late reverberation power spectral density estimators", IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
[3] Braun, S. and Habets, E. A. P., Linear prediction based online dereverberation and noise reduction using alternating Kalman filters, IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
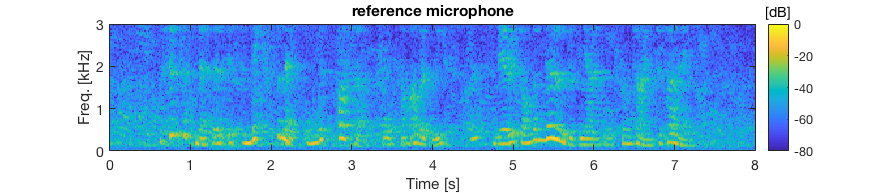
Real recording
- 4 microphone uniform linear array with 3 cm spacing
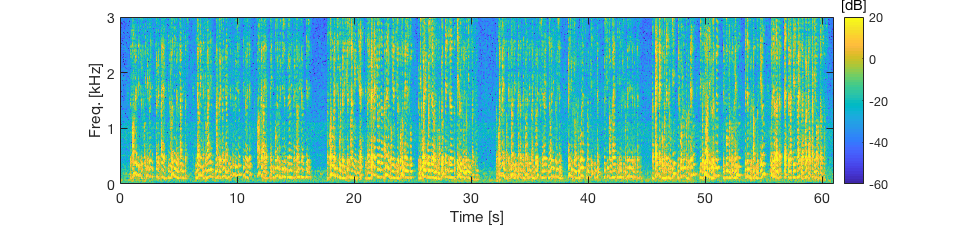
Measured RIRs + pink noise
- 4 microphone linear array
- T60 = 630 ms, 4 m distance
- SNR = 20 dB
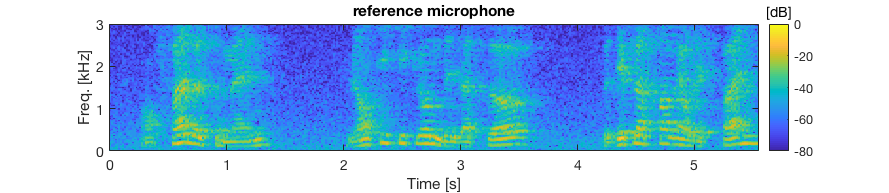
Measured RIRs + babble noise
- 4 microphone linear array
- T60 = 630 ms, 4 m distance
- SNR = 12 dB