

Multi-Channel Wind Noise Reduction Using the Corcos Model
D. Mirabilii and E. A. P. Habets
Published in the Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), UK, 2019.
Abstract
Outdoor recordings of speech are often corrupted by wind noise, which is difficult to reduce due to its high non-stationarity. In this work, a multi-channel wind noise reduction method is presented, based on a joint estimation of the speech and wind noise power spectral densities (PSDs). In contrast with existing approaches that assume uncorrelated wind noise, the estimation phase is performed exploiting the spatial characteristics of wind noise measured by closely-spaced microphones, here approximated by a fluid-dynamics model, termed the Corcos model. Recently developed closed-form estimators are exploited, i.e., the ones presented in [1] for dereverberation. The optimal solution of the joint estimation is obtained by minimizing the Frobenius norm of a composite error matrix, i.e., the difference of the noisy observations covariance matrix and its analytical model, where the spatial coherence matrix is defined by the Corcos model. An additional contribution is the employment of a frequency dependent trade-off parameter in the reduction phase, given by the ratio of the difference-signal power to the sum-signal power of a sub-set of two microphones, described in [2]. In particular, the latter is exploited to control the amount of noise reduction against speech distortion by means of a parametric multi-channel Wiener filter. The proposed approach can be also used to reduce mutually uncorrelated wind noise, replacing the spatial coherence matrix given by the Corcos model with an identity matrix. An evaluation in terms of speech quality and signal-to-noise ratio improvements shows increased performance of the proposed approach compared to an existing multi-channel wind noise reduction algorithm, i.e., a maximum-likelihood approach [3].
Audio Examples
The following audio examples are the outcome of the experiment described in Section 5.2. The number of microphone used is four. The wind noise samples are generated by the simulation approach presented in [4] and mixed with two different speakers (one male and one female) at 0 dB of input SNR. The speech is kept in the end-fire position. The direction of arrival of the speech is assumed to be known. The wind noise contributions exhibit a spatial coherence approximated by the Corcos model with the following parameters:
- inter-sensor distance of 4 mm
- convective turbulence speed of 1.8 m/s
- stream direction of 0° with respect to the microphone axis
The processing scheme are the following:
- ML-based MVDR: minimum-variance-distortionless response beamforming based on the maximum-likelihood PSD estimators [3]
- FN-based MVDR: minimum-variance-distortionless response beamforming based on the Frobenius norm PSD estimators
- ML-based MWF: multi-channel Wiener filter based on the maximum-likelihood PSD estimators [3]
- FN-based MWF: multi-channel Wiener filter based on the Frobenius norm PSD estimators
- ML-based PMWF: parametric multi-channel Wiener filter based on the maximum-likelihood PSD estimators [3] + proposed trade-off parameter
- FN-based PMWF: parametric multi-channel Wiener filter based on the Frobenius norm PSD estimators (proposed approach)
Note: Please use the Chrome or Safari browser for optimal audio/video synchronization. If you encounter playback problems, please reload the page.
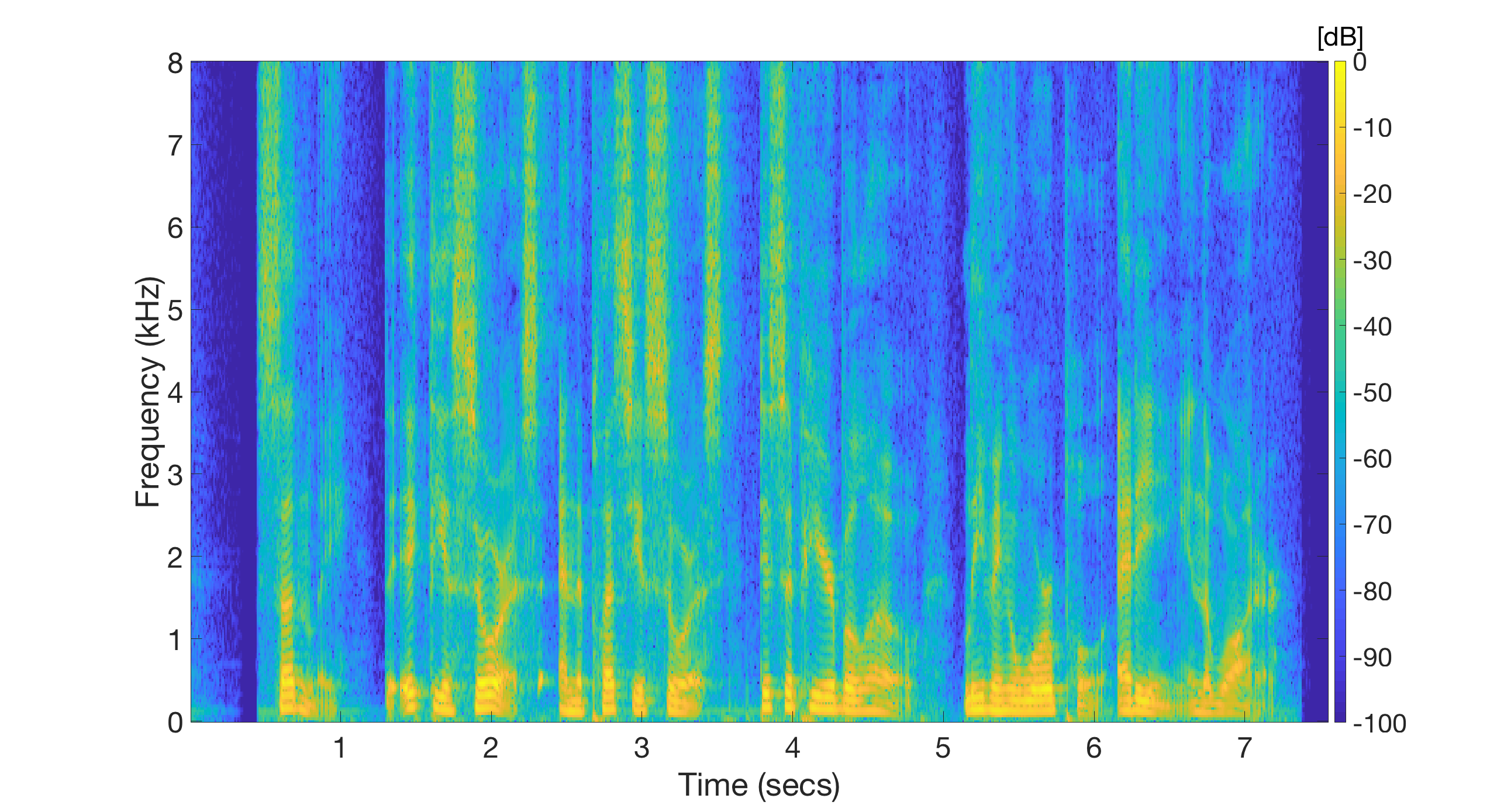
Example 1: Male speaker
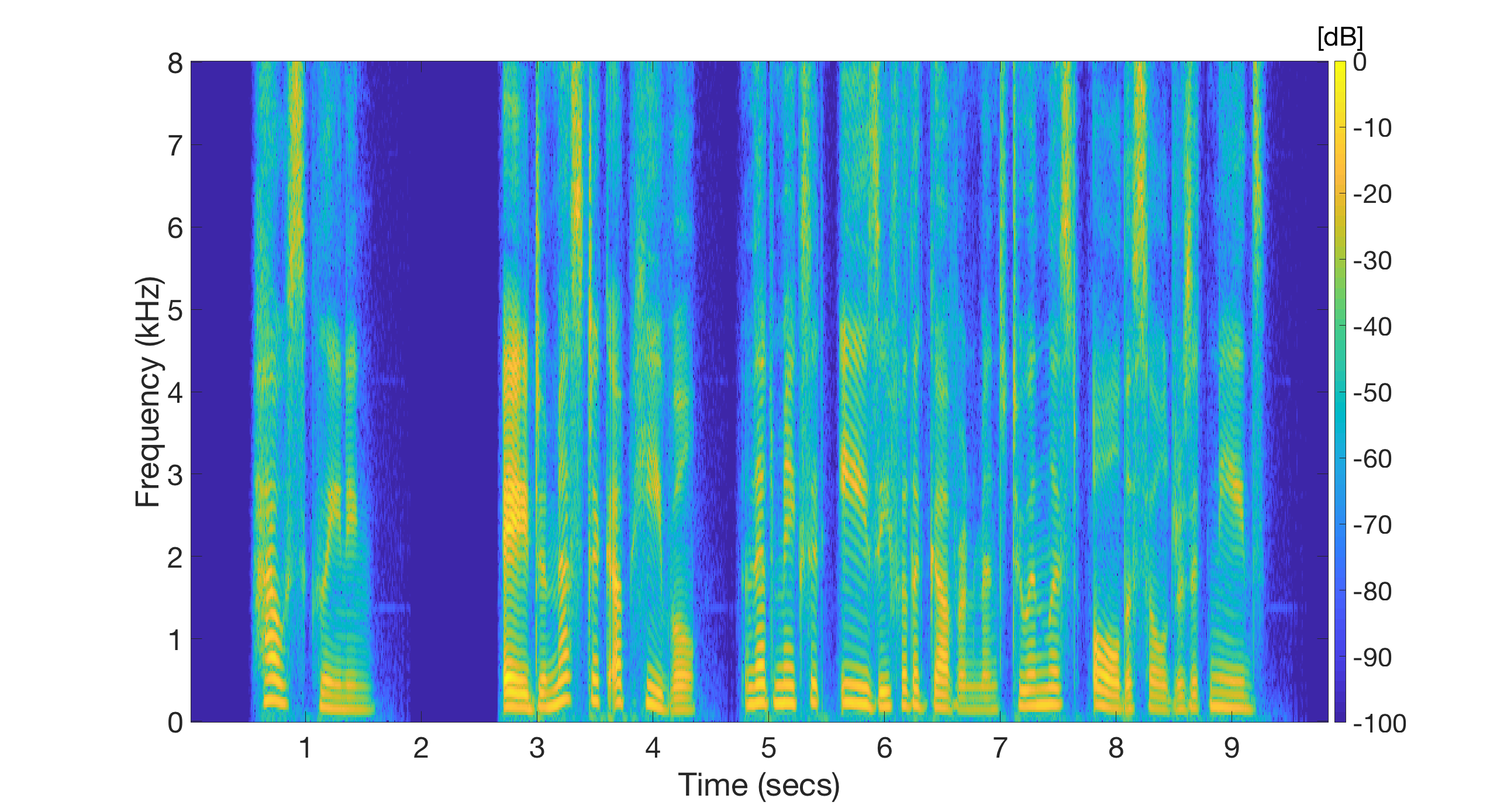
Example 2: Female speaker
References
[1] O. Schwartz, S. Gannot, and E. A. Habets, Joint estimation of late reverberant and speech power spectral densities in noisy environments using Frobenius norm, in Proc. European Signal Processing Conf. (EUSIPCO), 2016.
[2] D. Mirabilii and E. A. P. Habets, On the difference-to-sum power ratio of speech and wind noise based on the Corcos model, in Proc. IEEE Intl. Conf. on the Science of Electrical Engineering (ICSEE), 2018.
[3] P. Thuene and G. Enzner, Maximum-likelihood approach to adaptive multichannel-wiener postfiltering for wind-noise reduction, in Proc. of the ITG Conference on Speech Communication, pp. 1–5, VDE, 2016.
[4] D. Mirabilii and E. A. Habets, Simulating multi-channel wind noise based on Corcos model, in Proc. Intl. Workshop Acoust. Echo Noise Control (IWAENC), 2018. Code available at https://github.com/ehabets/Wind-Generator