Spotforming: Spatial Filtering with Distributed Arrays for Position-Selective Sound Acquisition
Maja Taseska and Emanuel A. P. Habets
Published in the IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016.
Abstract
Hands-free capture of speech often requires extraction of speech sources from certain locations, while reducing interferers and background noise. State-of-the-art methods for spatially-selective sound acquisition are based on data-dependent spatial filters computed using the power spectral density (PSD) matrices of the desired and the undesired signals. The performance of the filters is determined by the accuracy of the PSD matrices which need to be estimated from the microphone signals. The PSD matrix estimation is a challenging problem, especially in scenarios with multiple sources, whose number and locations may vary over time. Existing frameworks often assume that known periods exist where only desired or undesired signals are active, and the PSD matrices are estimated during these periods. Clearly, this is a very restrictive requirement for real applications where such periods need to be detected from the data, or might not even exist. In this work, we propose a spatial filtering framework, referred to as spotforming, where the goal is to extract signals that originate from a given spot of interest (SOI). To achieve position-based spatial selectivity, the signals from distributed arrays are used, resulting in larger spatial selectivity compared to arrays of closely spaced microphones. A minimum Bayes risk signal detector based on bin-wise position estimates is used to estimate the PSD matrices of the desired and undesired signals. The proposed detector allows for accurate estimation and tracking of the PSD matrices in challenging multi-talk situations, without requiring any prior information, except the location and orientation of the arrays.
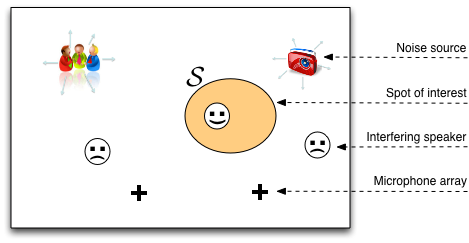
Figure 1: Setup
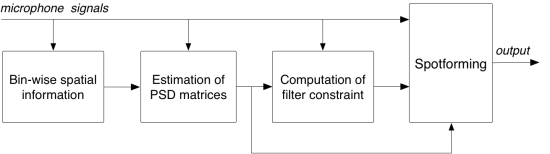
Figure 2: High-level block diagram of the spotforming framework
Setup
Figure 3: Illustration of the scenarios used for the experiments
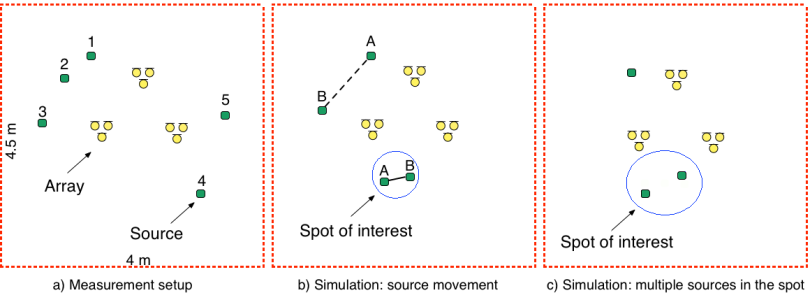
Figure 3a: Measurements were carried out in a room with reverberation time T60 of approx. 180 ms. Three circular arrays with diameter 2.9 cm and three DPA microphones per array were arranged as illustrated. The room impulse responses (RIRs) between each of the positions 1-5 and the microphones were measured, where five GENELEC loudspeakers located at positions 1-5 were used as sources. For more details about the measurement setup please refer to Section V of the paper. This setup is used in Experiments 1-3. To investigate the effects of reverberation, the same setup was also simulated, with the freedom to vary the reverberation time T60 (see Experiment 4).
Figure 3b: To examine the spotformer performance with moving sources, we simulated a moderately reverberant scenario with T60 of 300 ms. The desired source traverses the trajectory A-B-A-B-A (solid line), whereas the interferer traverses A-B-A (dotted line), during continuous double talk of 20 seconds. This setup is used in Experiment 5.
Figure 3c: In certain applications, especially when the size of the spot gets larger, multiple desired sources in the spot might be active, for instance, as shown in Figure 2c. A spotformer constraint that is suited for such scenarios is proposed in the paper and shown to outperform constraints that are derived from a single-source model. This setup is used in Experiment 6.
For detailed description of each experiment, the evaluation results and the discussion please refer to the respective paragraph in Section V of the paper. In the following, sound examples related to each of the experiments are given.
NOTE: The audio signals below are obtained only by applying the spatial filter, i.e., the MVDR-based spotformer. Further significant reduction of the residual undesired signal can be achieved by post-filtering. The current samples aim to demonstrate the potential of the spatial processing only.
Experiment 1
In all cases the spot is circular with radius 0.4 m. For the computation of the spotformer in these sound examples the detector with training was used. The spot-signal-to-noise-ratio was 6 dB in all examples.
- Two sources scenario, Source 5 is a desired source inside the spot, and Source 4 is an interferer.
- Three sources scenario, source 1 is a desired source inside the spot, and Sources 2 and 3 are interferers.
- Note that as Source 2 (male interferer) is located very near to the spot, it is less reduced than Source 3 (female interferer)
- Four sources scenario, Source 1 is a desired source inside the spot, and Sources 2,3 and 4 are interferers.
Experiment 2
The goal in this experiment is to demonstrate the advantage of the proposed data-dependent spotformer over the fixed constraint spotformer in dynamic scenarios. Such a scenario is obtained from the measurement data (Setup in Figure 2a) in the following manner: a circular spot with radius 0.4 m is centered at source position 1. The first ten seconds Source 1 and an interferer located at position 3 are simultaneously active, while the next ten seconds the desired source and two interferers located at positions 4 and 5 are active. For the computation of the spotformer in these sound examples the detector with training was used.
Experiment 3
In this experiment the advantage of incorporating training is demonstrated. Measured data was used from the setup in Figure 2a, where the desired source and the spot centre were at position 2. Two multi-talk scenarios were considered: in the first one an interferer at position 3 was active (relatively near to the spot), with input SIR of 0 dB, and in the second one an interferer at position 4 (relatively far from the spot) was active with input SIR of 1.5 dB. Sound examples only for the SP-based constraints are shown, as the focus is the comparison between the spotformer with training, and the one without training, as the spot radius increases.
- Interferer at position 3.
- Notice the better interference reduction of the spotformer that uses detector with training, as the spot radius increases.
- Notice that as the third array is relatively far from both the desired and undesired source, using all three arrays for spotforming does not improve the performance over using one or two arrays. On the contrary, the desired signal is more distorted and there are more artefacts in the undesired signal residual.
Experiment 4
To demonstrate the performance of the spotformer in a more reverberant environment, below sound examples from a simulated shoe-box room with reverberation time T60 of 400 ms are given. The input spot-signal-to-noise ratio was 9 dB. The main cause for performance degradation as the reverberation increases is the detection errors due to inaccurate position estimates. Nevertheless, the spotformer achieves certain amount of undesired signal reduction and dereverberation. Sound examples are given only for the detector with training, and for the GEVD-based spotformer constraint.
- Interferer far from the spot (>1.5 m)
- Note that as the reverberation increases, the estimation of the RTF vectors when using all arrays is more challenging, resulting in high signal distortion. However, the spotformer with one array provides a good tradeoff between undesired signal reduction and desired signal distortion, even in highly reverberant environments.
- Interferer near the spot (0.5 m - 1 m), reverberation time T60 is 400 ms
Experiment 5
This experiment illustrates the performance of the spotformer for moving sources (see Figure 2b). The scenario was simulated in a shoe-box room with reverberation time T60 of 300 ms and input spot-signal-to-noise ratio of 6 dB, which represents a significant level of babble noise.
-
Note that the GEVD-based spotformer constraint introduces more audible artefacts compared to the EVD-based and the SP-based constraints. The distortion of the GEVD-based spotformer was also higher in the static scenarios. Nevertheless in the scenarios with moving sources the difference is more audible.
-
Similarly as in the previous experiments, using all the arrays for spotforming introduces more distortion due to the increased sensitivity of the RTF vectors to detection errors, compared to when using only one array.
Experiment 6
In this experiment, the spotformer performance when two desired sources are in the spot is investigated. The two fixed constraints described in the paper are applied (see Secion III-B in the paper), the GEVD-based constraint using 1D signal subspace (i.e. based on a single source model), and the GEVD-based constraint using 2D signal subspace. Only the sound examples for spotforming with one array are shown below.
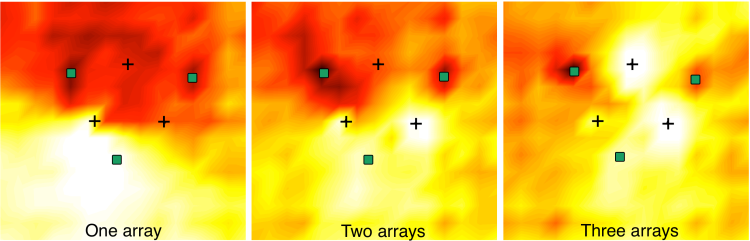
Illustration of the spotformer spatial selectivity pattern
A snapshot of the spotformer coefficients from all frequencies at a given frame was taken and the coefficients were applied to source signals located at different positions in the room, sampled on a square grid of 10 positions per meter. For each position, the ratio of the source power at the input to the source power at the output of the spotformer was recorded. The colormap is fixed to [1,11] dB (brightest to darkest). The source in the bright region is the desired source located in the spot, while the largest signal attenuation is achieved at the location of the interferers, illustrating the ability of the spotforming framework to blindly localize the interfering sources and create spatial nulls at their locations. The plot also illustrates the fact that while multiple arrays increase the spatial selectivity, they also lead to increased spot signal distortion.